
7月1日,当MLPerf发布了最新的1.0基准测试结果时,毫无悬念,英伟达再次霸榜。
MLPerf由图灵奖得主大卫·帕特森(David Patterson)联合谷歌、斯坦福、哈佛大学等单位共同成立, 每年MLPerf会定期进行AI训练和推理新测试,并添加代表 AI 最先进技术的新工作负载。
在最新一轮的基准测试MLPerf 1.0中,MLPerf Training v1.0由八种不同的工作负载组成,涵盖广泛的应用场景,包括视觉、语言、推荐和强化学习。
MLPerf Inference v1.0 在七种不同类型的神经网络中测试了七种不同的负载,其中三个用于计算机视觉,一个用于推荐系统,两个用于语言处理,一个用于医学成像。
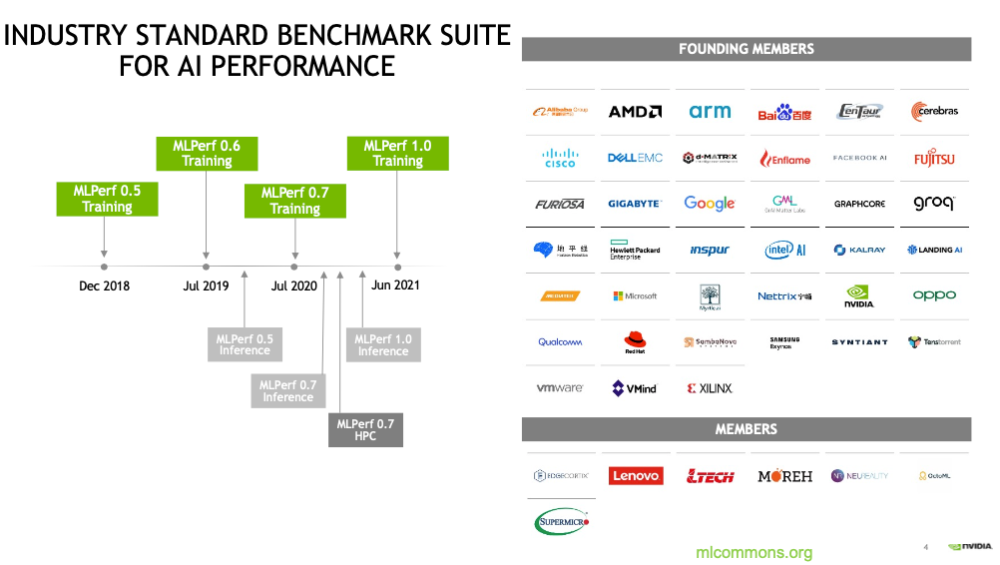
这是英伟达生态系统第四次参加MLPerf的训练测试,除英伟达之外,戴尔、富士通、技嘉、浪潮、联想、宁畅、超微一起参与了本轮测试,使用NVIDIA A100 Tensor Core GPU,推出12套商用系统,占所有提交作品的四分之三。
重点是,唯一进行了全部8项测试的只有英伟达及其合作伙伴。
更快更聪明 打破八项基准测试记录
MLPerf 1.0基准测试基于当今最常用的AI工作负载和场景,与之前相比,增加了会议识别RNN-T和医学图像划分UNet-3D两种。其余六种是自然语言处理网络BERT、深度学习推荐模型DLRM、对象检测网络SSD和Mask R-CNN、强化学习网络MiniGo和用于图像分类的ResNet-50。

在这八项测试中,A100 GPU均创纪录。英伟达数据中心计算产品管理高级总监Paresh Kharya分享了DGX SuperPOD和DGX A100在测试中的表现。
训练基准测试聚焦用户最关心的问题,比如训练一个全新AI模型所需的时间,在最新一轮MLPerf基准测试结果中,每一项模型训练中英伟达AI平台都可在最短的时间内完成,并在商用提交类别的所有八项基准测试中创下了性能纪录。
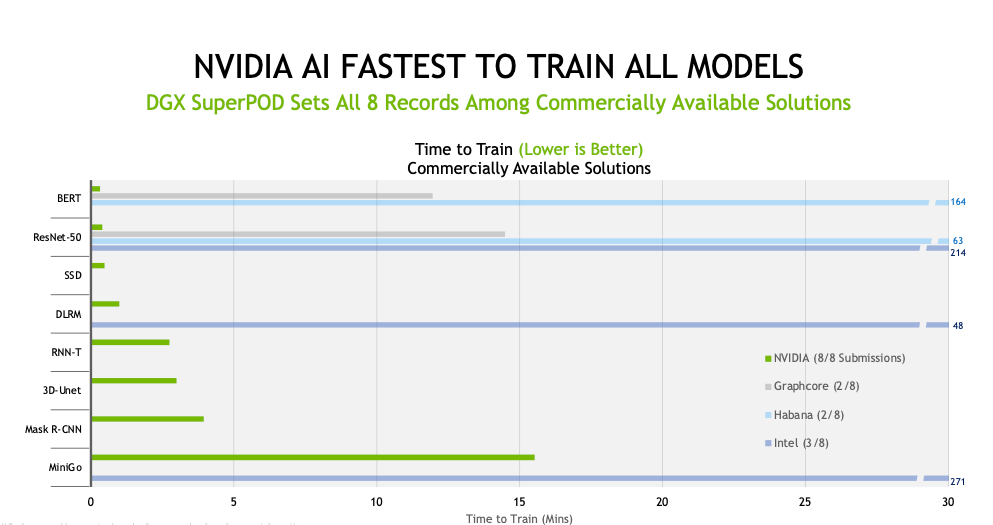
基于 NVIDIA DGX SuperPOD 的Selene在所有八项测试中均创下纪录
可以看出,这次测试是英伟达在Selene进行的大规模测试。
从最新的TOP500排名来看,Selene是世界上最快的商业人工智能超级计算机之一,Selene是英伟达6位工程师仅花费约25天即搭建完成的,传统超算系统在最理想情况下也需要数十名工程师花费数月时间完成,可以说实现了一个不小的工程奇迹,这与NVIDIA DGX SuperPOD架构超强的高可扩展的模块化设计特点分不开。
此外,在网络互连结构方面,Selene采用了200G HDR的InfiniBand技术,同时将280个节点采用胖树拓扑互连,结合NVIDIA最新的节点间通信加速技术SHARPTM2.0,让Selene能够在保障足够网络带宽的同时,降低节点间通信延时,提高大规模运算处理效率。
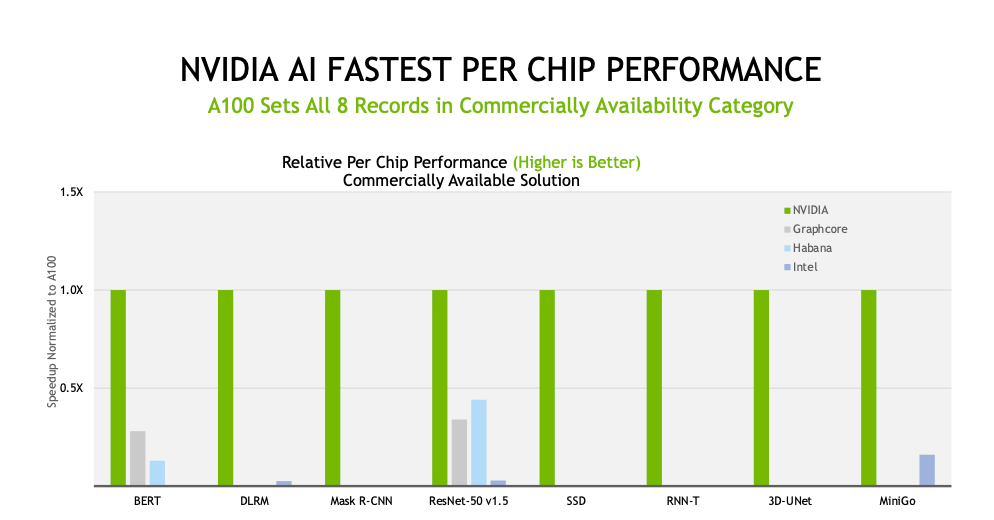
A100 GPU在商用系统类别的所有八项测试中均创下纪录
而对于需要最高性能的大规模工作,这恰恰是英伟达的优势所在,英伟达创纪录地调集连接了4096个GPU的资源,英伟达及其合作伙伴在八项精准测试中都创下纪录。
左右手协同 软硬全栈并进
MLPerf测试结果再次展示了英伟达作为技术新贵的优势,在过去两年半的时间内,英伟达将性能提高了多达6.5倍,充分证明了包括GPU、系统和软件在内的全栈式NVIDIA平台的实力。
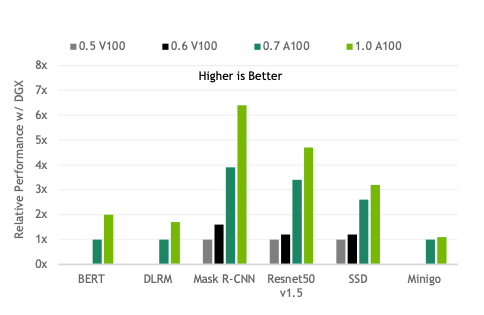
NVIDIA AI 通过全栈的改进,持续带动性能提升。
与去年相比,基于英伟达DGX SuperPOD和DGX A100的系统测试表现均有较大提升。在DLRM(深度学习推荐模型)测试中,基于DGX SuperPOD系统得分更是提升了3.5倍。

从硬件来看,这次征战的英伟达DGX A100 GPU,是第二次参与MLPerf测试,A100是Selene优异性能的保障,作为英伟达第八代数据中心GPU,采用Ampere架构,实现了若干硬指标(具体可参见之前E企研究院分析:NVIDIA安培GPU:从TOP500走向云智应用)。
A100中包含了430个第三代Tensor Core核心应用了NVLink 3.0技术,GPU间通信带宽达到600GB/s,是NVlink 2.0的两倍,最高可支持16张A100 GPU的互连。此外,A100中实现了多实例GPU技术,最多可分割成7个独立的GPU实例。
英伟达不仅在硬件层面提供更强的能力,软件算法和数据结构改进也提供了更高的效率,可谓基础设施换代的左右手,使用AI优化技术,A100 GPU能够游刃有余的应对多用户、不同规模AI负载对于GPU硬件资源的需求。
Selene的软件环境主要基于NVIDIA的NGC容器化资源库来实现,它包含多种类面向深度学习和高性能计算的GPU优化软件工具,支持全栈范围内的性能优化,同时支持容器化的混合编程环境,这样的一套NVIDIA可控的软硬件环境可以为高性能计算和AI应用的用户提供方便的编程开发环境
其中,CUDA Graphs,是英伟达新的异步任务图像(Task-Graph)编程模型,可以提升内核启动和执行的效率。此外,大规模测试中使用的是NVIDIA SHARP。该软件能够在网络交换机内整合多项通信工作,从而减少网络流量和等待CPU的时间。
CUDA Graphs和SHARP的结合,使数据中心能够使用有史以来最多的GPU进行训练。在诸如自然语言处理等很多领域,随着AI模型参数增加到数十亿的量级,这样的组合恰能提供所需的强大能力。
生态伙伴齐上阵 简化客户选择流程
英伟达针对AI应用的优化技术,使得A100 GPU能够游刃有余的应对多用户、不同规模AI负载对于GPU硬件资源的需求,也推动了HPC和AI的融合,同时有力推进了大规模分布式AI应用的研究。
同时,异构计算和AI应用,英伟达的技术路线踩对了技术的发展脉搏,也匹配了时代的应用需求。这次参与测试的生态伙伴选用的是包含从入门级边缘服务器,到可容纳数千个GPU的AI超级计算机。包括参与最新基准测试的七家合作伙伴在内,共有二十多家云服务供应商和OEM厂商的产品或采用了NVIDIA A100 GPU,或计划为在线实例、服务器采用NVIDIA A100 GPU,包括近40款NVIDIA认证系统。
而在英伟达生态伙伴的共同努力下,可为客户提供各种部署模型选择,提供业内最高的性价比——从按分钟出租的实例,到本地服务器和托管服务。
比如德国癌症研究中心将3DUNet等创新技术引入医疗市场。作为行业标准的MLPerf基准测试提供了相关的性能数据,能够帮助IT机构和开发者找到合适的解决方案,以加速特定项目和应用。”
而制造行业的典范三星也参考MLPerf基准测试,使用AI来提高产品性能和制造效率。
用AI创新技术赋能各行各业,英伟达正在从硬件到软件不断加持企业打造强大的AI基础设施;而基于与生态伙伴的联合创新,企业根据场景适配产品方案,推动自身业务发展,促进业务智能升级。













