
有了AI设计芯片,我再也不相信「摩尔定律」了!

近日,由Jeff Dean领衔的谷歌大脑团队以及斯坦福大学的科学家们,在一项研究中证明:
「一种基于深度强化学习(DL)的芯片布局规划方法,能够生成可行的芯片设计方案。」

AI能设计芯片,这还不够震撼。
只用不到 6 小时的时间设计出芯片才惊人!

Jeff Dean:我们用AI,6小时就能设计一款芯片,敢信?
为了训练AI干活儿,谷歌研究员可真花了不少心思。
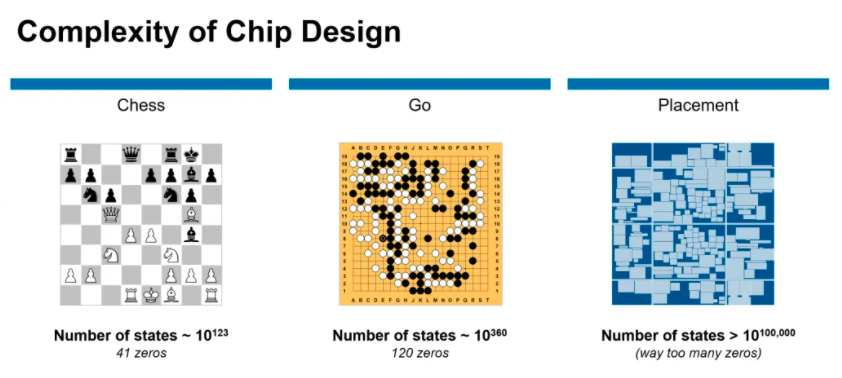
与棋盘游戏,如象棋或围棋,的解决方案相比较,芯片布局问题更为复杂。
在不到6小时的时间内,谷歌研究人员利用「基于深度强化学习的芯片布局规划方法」生成芯片平面图,且所有关键指标(包括功耗、性能和芯片面积等参数)都优于或与人类专家的设计图效果相当。
要知道,我们人类工程师往往需要「数月的努力」才能达到如此效果。
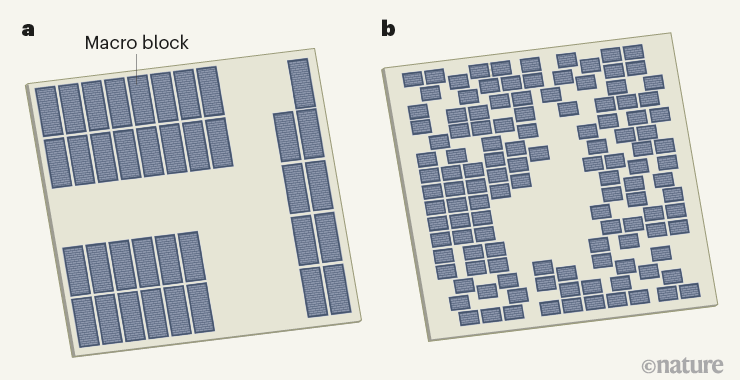
人类设计的微芯片平面图与机器学习系统设计
具体是什么方法呢?
在nature的介绍中,谷歌研究人员将芯片布局规划方法当做一个「学习问题」。
潜在问题设计高维contextual bandits problem,结合谷歌此前的研究,研究人员选择将其重新制定为一个顺序马可夫决策过程(MDP) ,这样就能更容易包含以下几个约束条件:

(1)状态编码关于部分放置的信息,包括 netlist (邻接矩阵)、节点特征(宽度、高度、类型)、边缘特征(连接数)、当前节点(宏)以及 netlist 图的元数据(路由分配、总线数、宏和标准单元簇)。
(2)动作是所有可能的位置(芯片画布的网格单元) ,当前宏可以放置在不违反任何硬约束的密度或阻塞。
(3)给定一个状态和一个动作,「状态转换」定义下一个状态的概率分布。
(4)奖励:除最后一个动作外,所有动作的奖励为0,其中奖励是代理线长、拥塞和密度的负加权,如下所述。
研究人员训练一个由神经网络建模的策略(一个RL代理) ,通过重复的事件(状态、动作和奖励的顺序) ,学会采取将「累积奖励最大化」的动作(见Fig. 1)。该项目使用邻近策略优化(PPO)来更新策略网络的参数,给定每个放置的累积奖励。
通过训练一个智能体,用累计奖励最大化,让AI优化芯片布局的能力持续增强。
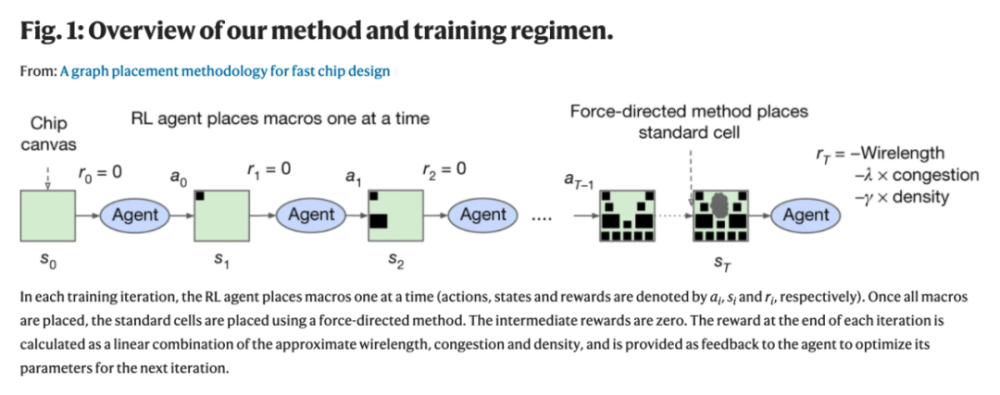
在每个训练迭代中,RL 代理一次放置一个宏(动作、状态和奖励分别由 ai、 si 和ri表示)。一旦所有的宏被放置,标准单元格被放置使用一个力定向的方法。中间奖励为零。每次迭代结束时的奖励计算为近似线长、阻塞和密度的线性组合,并作为反馈给代理以优化下一次迭代的参数。
研究人员将目标函数定义如下:
如前所述,针对芯片布局规划问题开发领域自适应策略极具挑战性,因为这个问题类似于一个具有不同棋子、棋盘和赢条件的博弈,并且具有巨大的状态动作空间。
为了应对这个挑战,研究人员首先集中学习状态空间的丰富表示。
谷歌研究人员表示,我们的直觉是,能够处理芯片放置的一般任务的策略也应该能够在推理时将与新的未见芯片相关的状态编码为有意义的信号。
因此,研究人员训练了一个「神经网络架构」,能够预测新的netlist位置的奖励,最终目标是使用这个架构作为策略的编码层。

为了训练这个有监督的模型,就需要一个大型的芯片放置数据集以及相应的奖励标签。
因此,研究人员创建了一个包含10000个芯片位置的数据集,其中输入是与给定位置相关联的状态,标签是该位置的奖励。
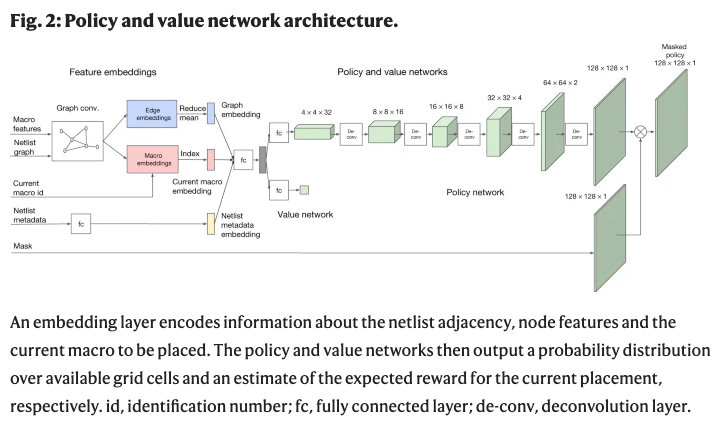
为了准确地预测奖励标签并将其推广到未知数据,研究人员提出了一种基于边的图形神经网络结构,称之为Edge-GNN (Edge-Based Graph Neural Network)。
在Edge-GNN中,研究人员通过连接每个节点的特征(包括节点类型、宽度、高度、 x 和 y 坐标以及它与其他节点的连通性)来创建每个节点的初始表示。
然后再迭代执行以下更新: (1)每个边通过应用一个完全连通的网络连接它连接的两个节点更新其表示,(2)每个节点通过传递所有的平均进出边到另一个完全连通的网络更新其表示。节点和边的更新如下面方程所示。

Edge-GNN的作用是嵌入netlist,提取有关节点类型和连通性的信息到一个低维向量表示,可用于下游任务。基于边缘的神经结构对泛化的影响如Fig. 2所示。
研究人员首先选择了5个不同的芯片净网表,并用AI算法为每个网表创建2000个不同的布局位置。
该系统花了48个小时在「英伟达Volta显卡」和10个CPU上「预训练」,每个CPU都有2GB的RAM。
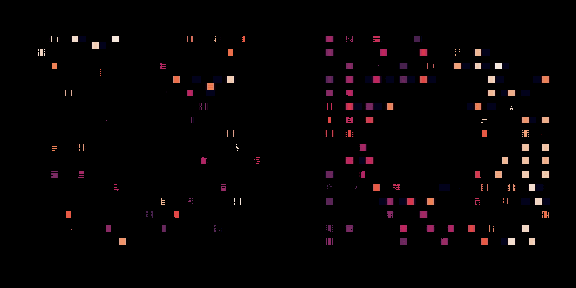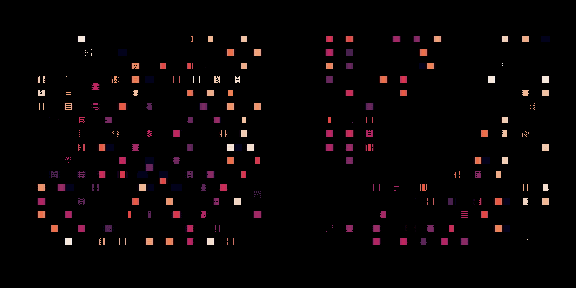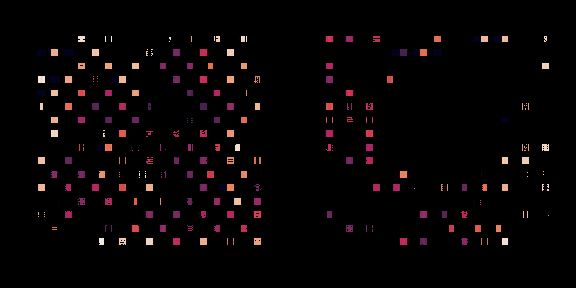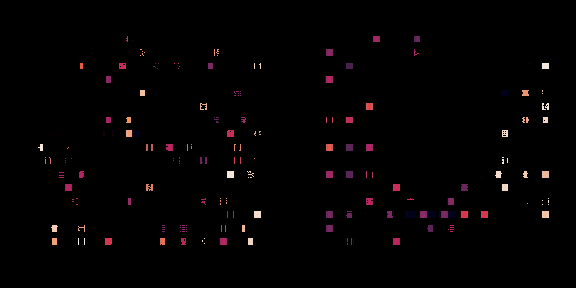
左边,策略正在从头开始训练,右边,一个预训练的策略正在为这个芯片进行微调。每个矩形代表一个单独的宏放置
在一项测试中,研究人员将他们的系统建议与手动基线——谷歌TPU物理设计团队创建的上一代TPU芯片设计——进行比较。
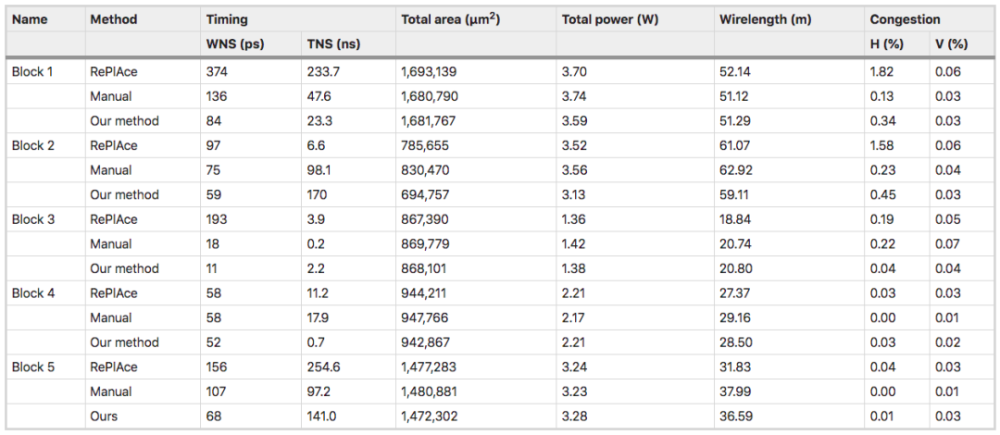
结果显示,系统和人类专家均生成符合时间和阻塞要求的可行位置,而AI系统在面积、功率和电线长度方面优于或媲美手动布局,同时满足设计标准所需的时间要少得多。
TPU 秘密武器
最新的「微调技术」将用来设计即将推出的,以前未宣布的谷歌张量处理单元(TPU)的生成。
也就是未来的第五代芯片TPU v5。
不久前的谷歌IO大会上,谷歌推出了最新的AI定制第四代芯片TPU v4 ,速度是v3的两倍。

v4的性能相比前一代提升了10倍多,专门用于加速人工智能。
一个TPU pod的计算能力达到了每秒百亿亿次浮点计算的级别,相当于一千万台笔记本电脑之和。

以前要想获得1个exaflop(每秒 10 的 18 次方浮点运算)的算力,通常需要建立一个定制的超级计算机。
TPU是谷歌的第一批定制芯片之一,当包括微软在内的其他公司决定为其机器学习服务采用更灵活的FPGA时,谷歌很早就在这些定制芯片上下了赌注。

虽然谷歌团队的系统被用于设计下一代谷歌TPU,但研究人员认为,它可以应用于芯片设计以外的有影响力的放置规划问题,包括城市规划、疫苗测试分发和大脑皮层映射等一系列应用。
芯片设计也能「迁移学习」?还可大幅缩短训练时间
如果能利用先前的设计经验,实现迁移学习,将大大缩短训练时间和成本。
如果在芯片设计中使用「预训练」策略能否产生更好的结果?
后续实验中,研究人员使用预训练策略生成的放置位置质量,与从头训练策略网络生成的放置位置质量进行比较。

从无到有的训练与不同时间量的微调
训练的数据集由 TPU Block 和 开源 Ariane RISC-V CPU 组成。在每一个实验中,都对除目标块外的所有块预先训练策略。
研究人员使用Zero-Shot在不到 1 秒钟的时间内就生成了放置位置。如果根据特定设计的细节对预训练的策略网络进行2-12个小时的微调。
结果发现,从零开始训练的策略需要更长的时间才能收敛,即使在 24 小时之后,结果(由奖励函数评估)也比微调策略在 12 小时内达到的效果差。
这说明预训练所学到的权重和专家的设计经验起了很关键的作用——为新的看不见的块生成更高质量的放置方案。
最终结果显示,经过预训练的策略网络在微调过程开始时就获得了较低的布置成本,并且比从头开始训练的策略网络要快30个小时以上。
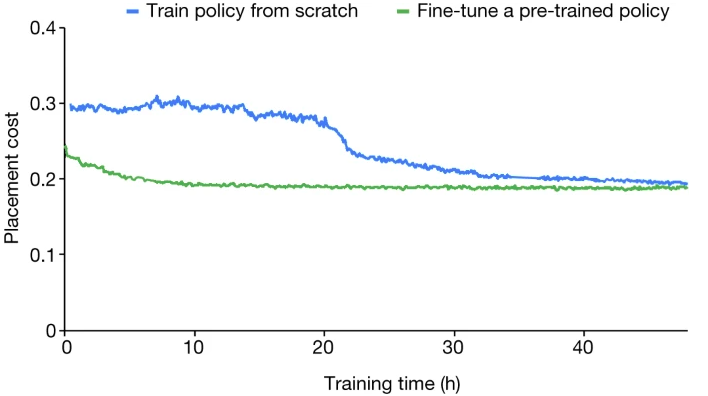
Ariane RISC-V CPU30 从零开始训练与从预先训练的策略网络开始训练的收敛图
接下来,研究人员在三个不同的训练数据集上对策略网络进行了预训练(小数据集是中型数据集的一个子集,而中型数据集是大型数据集的一个子集)。
然后在相同的测试块上微调预训练的策略网络,并对比不同训练时间下的成本。随着数据集的增大,生成的布置质量和在测试块上收敛的时间都会提高。
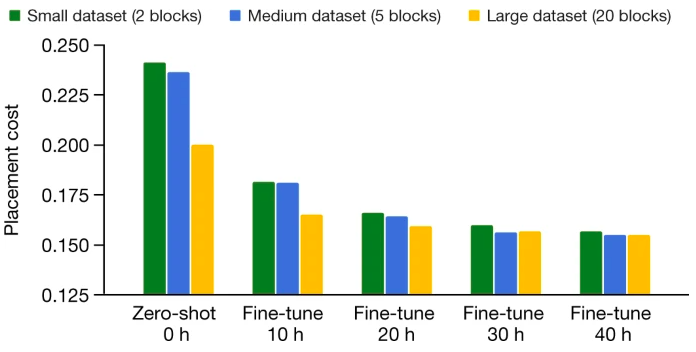
训练前数据集大小的影响
「我们的方法和人类专家都能产生可行的布局,而且符合芯片的时序和阻塞设计标准。我们在WNS、面积,功率和线长方面也优于或相当于人类专家的设计。但是,我们端到端的学习方法耗时仅6个小时,而手动布置需要一个缓慢的迭代优化过程,还需要专家干预,导致整个周期可能持续数周」。
AI设计芯片会抢走我们的饭碗吗?
21世纪最贵的是什么?人工。最便宜的是什么?人工智能。
芯片研发周期长、成本高,重度依赖设计。优秀的芯片设计师非常稀缺,基本都被几家老牌芯片大厂垄断,后起之秀很难在短期内挖到足够的资深设计师。
从零培养一个人类设计师很难,利用已有的数据从零训练一个AI设计师相比就简单多了。况且,AI不要工钱,不贪福利,不会罢工,永不疲惫。更重要的是,它随叫随到。

读者朋友们,你看好AI设计芯片吗?你认为如果AI连芯片都能设计,是否会威胁到芯片从业人员的工作岗位呢?是否意味着未来将可能出现AI制造AI?欢迎留言讨论。
来源:万物智能视界
声明:本文内容系作者个人观点,不代表传感器专家网观点或立场。更多观点,欢迎大家留言评论。













