
机器之心报道
编辑:力元
近年来,自然语言生成(NLG)是最突出的技术之一。来自 CMU 计算机科学系的语言技术博士生 Shrimai Prabhumoye 在本篇论文中对人机交互领域中的可控文本生成问题进行了深度的研究。
论文全长 103 页,共六章,从人类交流的三个方面:风格、内容、结构讨论了如何能够让机器听起来更像人,并提供了在神经文本生成中控制这些变量的深度学习解决方案。
机器之心对本篇论文的核心内容进行了介绍,感兴趣的读者可以阅读论文原文。

论文链接:https://www.cs.cmu.edu/~sprabhum/docs/proposal.pdf
论文概述
首先,作者概述了可以被操控的几个模块,操控这些模块可以实现有效的可控文本生成。作者为使用反向翻译的风格迁移提供了一种新颖的解决方案,并介绍了两个新任务,以利用非结构化文档的信息,来进入生成的过程。然后,作者为句子排序任务提供了一种新颖且优雅的设计,以学习有效的文档结构。最后,作者讨论了有关可控文本生成应用在道德伦理层面的考量。
可控文本生成技术
在第 2 章,作者将可控文本生成有关的论文串在了一起,并整理了有关这些任务和技术相似之处的知识。然后,作者组织了先前的工作,并提出了一个新的架构,其中包含 5 个可以更改以控制生成过程的模块:外部输出模块、顺序输入模块、生成器模块、输出模块、训练目标模块。最后,作者概述了代表控制向量以及将其并入生成过程的不同理论,还对这些技术进行了定性评估。
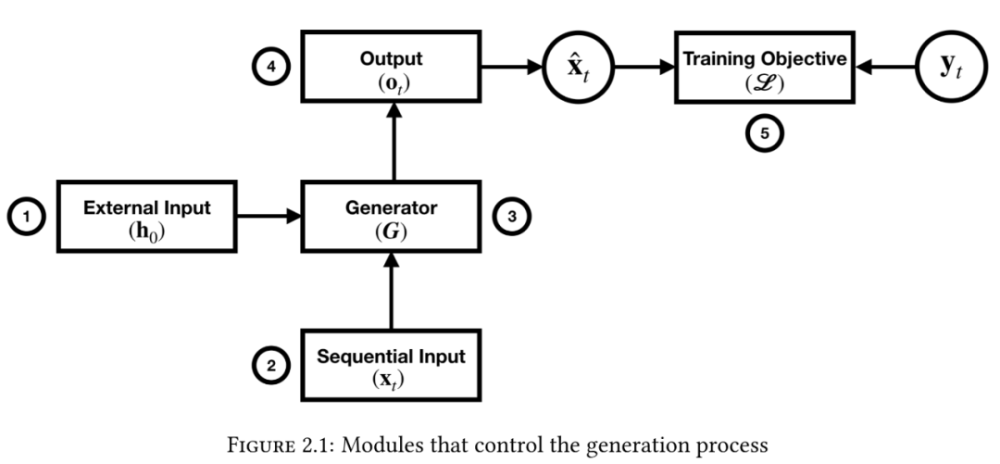
控制文本生成过程的模块
风格迁移
在第 3 章,作者描述了一种新颖的反向翻译方法,可以在非并行数据中执行风格迁移,以完成各种任务,例如:性别迁移、政治倾向迁移、情绪修改。作者还提供了对访问风格迁移方法的三个维度的自动评估和人工评估的见解,这三个维度包括:风格迁移准确性、含义保存和流利性。
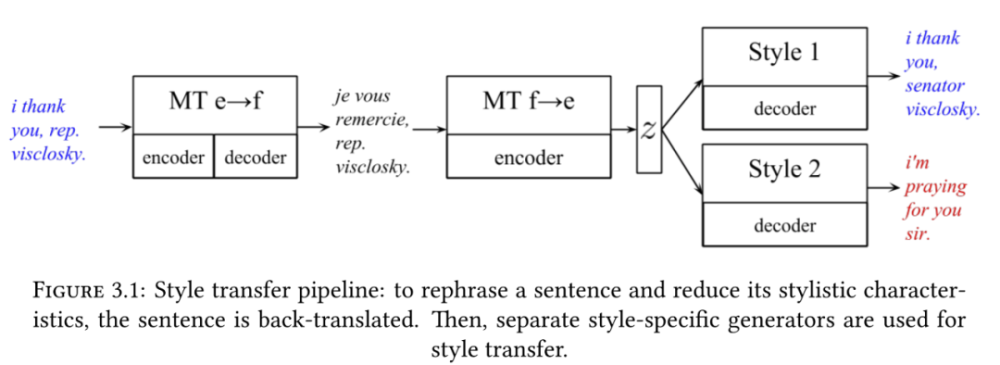
风格迁移 pipeline
内容与结构
在第 4 章,作者为两个不同领域的内容生成提出了两项新任务。首先是 Wikipedia 编辑生成任务:根据外部新闻文章和 Wikipedia 文章背景生成一个 Wikipedia 更新。第二个是对话响应生成:包括基于来自外部和当前对话历史的知识生成响应。最后,作者为基于 Wikipedia 编辑生成任务训练的模型提供了广泛的评估。
在第 5 章,作者宏观说明了捕捉文档结构的各种技术。并且,作者特别关注了句子排序的子任务,提出其新框架作为约束解决任务,然后基于问题的新设计介绍了一个新的模型。同时作者建议对此任务进行新的人工评估。

拥有维基百科访问权的用户 vs 没有维基百科访问权的用户
伦理道德
在第 6 章,作者探讨了对于可控文本生成方面的道德考量。作者概述了与 NLP 有关的各种道德问题以及讨论这些问题的必要性,还总结了伦理学的两个原理 - 泛化原理和功利主义原理。
作者介绍
在攻读 CMU 计算机科学系的语言技术 PhD 之前,Shrimai Prabhumoye 在印度国立技术学院攻读了本科,并于 2017 年 8 月获得了语言技术硕士学位。在此期间,她带领 CMU Magnus 团队参加了 Amazon Alexa 奖竞赛。在 CMU 期间,Shrimai Prabhumoye 还与他人共同设计了 NLP 计算伦理学课程,并于 2018 年春季首次在 CMU 开放了此课程。
论文目录如下:


迁移学习发展现状及案例探究
6月15日,机器之心最新一期线上分享邀请到本书作者、微软亚洲研究院研究员王晋东带来分享,介绍迁移学习的最新研究现状,带领大家从琳琅满目的研究工作中,找寻最本质的方法。













