
机器之心专栏
作者:秦禹嘉
在这篇被 ACL 2021 主会录用的文章中,研究者提出了 ERICA 框架,通过对比学习帮助 PLM 提高实体和实体间关系的理解,并在多个自然语言理解任务上验证了该框架的有效性。

近年来,预训练语言模型(PLM)在各种下游自然语言处理任务中表现出卓越的性能,受益于预训练阶段的自监督学习目标,PLM 可以有效地捕获文本中的语法和语义,并为下游 NLP 任务提供蕴含丰富信息的语言表示。然而,传统的预训练目标并没有对文本中的关系事实进行建模,而这些关系事实对于文本理解至关重要。

论文链接:https://arxiv.org/abs/2012.15022
开源链接:https://github.com/thunlp/ERICA
问题背景

传统的预训练目标没有对文本中的关系事实进行显式建模,而这些关系事实对于理解文本至关重要。为了解决这个问题,一些研究人员试图改进 PLM 的架构、预训练任务等,以更好地理解实体之间的关系。但是它们通常只对文本中的句子级别的单个关系进行建模,不仅忽略了长文本场景下多个实体之间的复杂关系,也忽略了对实体本身的理解,例如图1中所展现的,对于长文本来说,为了让PLM更加充分理解地单个实体,我们需要考虑该实体和其他实体之间的复杂关系;而这些复杂的关系的理解通常涉及复杂的推理链,往往需要综合多个句子的信息得出结论。针对这两个痛点,本文提出了实体区分任务和关系区分任务来增强PLM对于实体和实体间关系的理解。
文档级预训练数据收集

ERICA的训练依赖于大规模文档级远程监督数据,该数据的构造有三个阶段:首先从wikipedia中爬取文本段落,然后用命名实体识别工具(例如spacy)进行实体标注,将所有获得的实体和wikidata中标注的实体对应上,并利用远程监督(distant supervision)信号获得实体之间可能存在的关系,最终保留长度在128到512之间,含有多于4个实体,实体间多于4个远程监督关系的段落。注意这些远程监督的关系中存在大量的噪声,而大规模的预训练可以一定程度上实现降噪。作者也开源了由100万个文档组成的大规模远程监督预训练数据。
实体与实体间关系的表示

鉴于每个实体可能在段落中出现多次,并且每次出现时对应的描述(mention)可能也不一样,作者在使用PLM对tokenize后的段落进行编码后,取每个描述的所有token均匀池化后的结果作为该描述的表示,接着对于全文中该实体所有的描述进行第二次均匀池化,得到该实体在该文档中的表示;对于两个实体,它们之间的关系表示为两个实体表示的简单拼接。以上是最简单的实体/实体间关系的表示方法,不需要引入额外的神经网络参数。作者在文中还探索了其它的表示方法,并验证了所有方法相比baseline都有一致的提升。
实体区分任务

实体区分任务
实体区分任务旨在给定头实体和关系,从当前文档中寻找正确的尾实体。例如在上图中,Sinaloa和Mexico具有country的远程关系,于是作者将关系country和头实体Sinaloa拼接在原文档的前面作为提示(prompt),在此条件下区分正确的尾实体的任务可以在对比学习的框架下转换成拉近头实体和正确尾实体的实体表示的距离,推远头实体和文档中其它实体(负样本)的实体表示的距离,具体的公式如下所示:
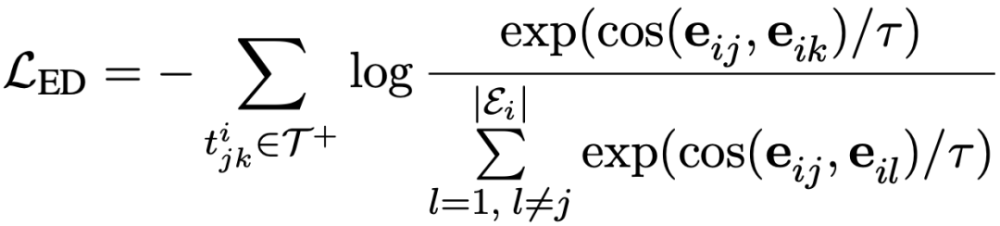
关系区分任务

关系区分任务
关系区分任务旨在区分两个关系的表示在语义空间上的相近程度。由于作者采用文档级而非句子级的远程监督,文档中的关系区分涉及复杂的推理链。具体而言,作者随机采样多个文档,并从每个文档中得到多个关系表示,这些关系可能只涉及句子级别的推理,也可能涉及跨句子的复杂推理。之后基于对比学习框架,根据远程监督的标签在关系空间中对不同的关系表示进行训练,如前文所述,每个关系表示均由文档中的两个实体表示构成。正样本即具有相同远程监督标签的关系表示,负样本与此相反。作者在实验中还发现进一步引入不具有远程监督关系的实体对作为负样本可以进一步提升模型效果。由于进行对比训练的两个关系表示可能来自于多个文档,也可能来自于单个文档,因此文档间/跨文档的关系表示交互都得到了实现。巧妙的是,对于涉及复杂推理的关系,该方法不需要显示地构建推理链,而是“强迫”模型理解这些关系并在顶层的关系语义空间中区分这些关系。具体的公式如下所示:
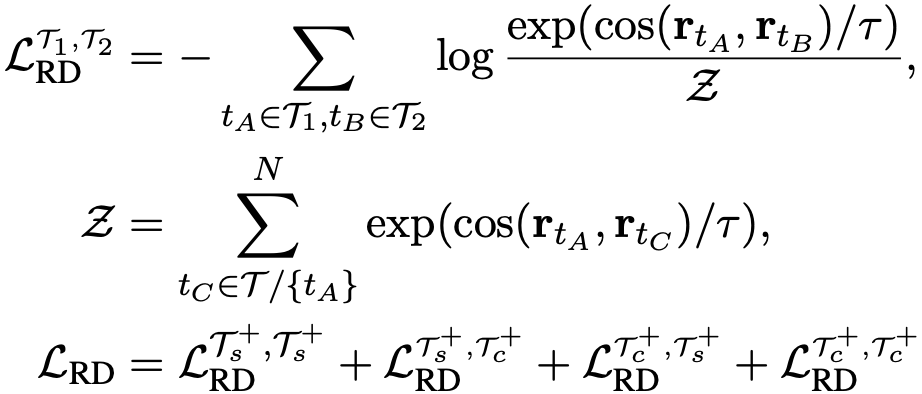
为了避免灾难性遗忘,作者将上述两个任务同masked language modeling (MLM)任务一起训练,总的训练目标如下所示:
实验结果
ERICA的训练不需要引入除了PLM之外的任何参数,并且对于任意模型均能够适配,具体的,作者采用了两个经典的PLM:BERT和RoBERTa,并对其进行一定时间的post-training,最后在文档级关系抽取、实体类别区分、问题回答等任务上进行了测试,并对比了例如CorefBERT, SpanBERT, ERNIE, MTB,CP等基线模型,验证了ERICA框架的有效性。具体结果如下:
a) 文档级关系抽取,模型需要区分文档中的多个实体之间的关系,这需要PLM对实体间关系有较好的理解。

文档级关系抽取(DocRED)
b) 实体类别区分,模型需要区分文本中的实体的具体类别,这需要PLM对实体本身有较好的理解。
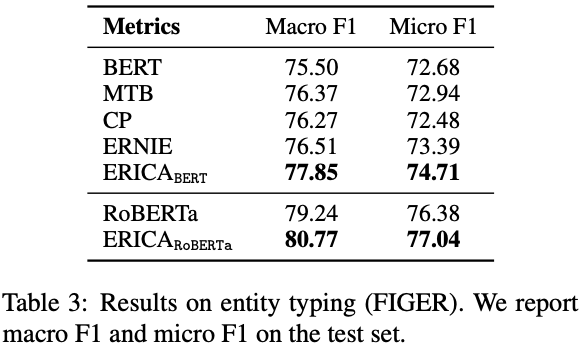
实体类别区分(FIGER)
c) 问题回答,作者测试了两种常见的问题回答任务:多选问答(multi-choice QA)和抽取式问答(extractive QA)。这需要PLM对实体和实体间关系有较好的理解。

多选问答(multi-choice QA)

抽取式问答(extractive QA)
分析
a) 消融分析(ablation study)。作者对ERICA框架中的所有组成成分进行了细致的分析,并证明了这些组成成分对于模型整体效果的提升是缺一不可的。
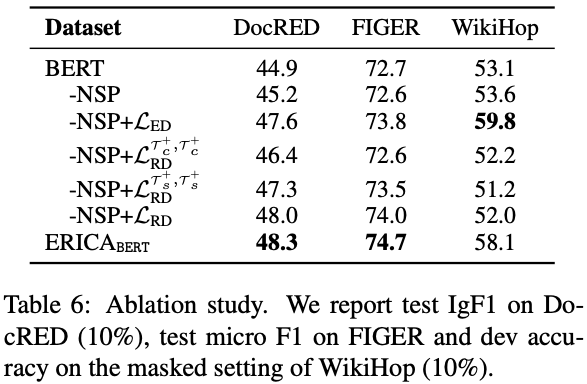
b) 可视化分析。作者对经过ERICA训练前后的PLM对实体和实体间关系的表示进行了可视化,结果如下图所示。通过ERICA的对比学习训练,PLM对于同类别的实体/实体关系的表示有明显的聚类现象,这充分验证了ERICA能够显著增强PLM对实体和实体间关系的理解。

c) 此外,作者分析了远程监督关系的多样性/预训练文档数量对于模型效果的提升。实验结果发现,更加多样的远程监督关系与更大的预训练数据集对于性能的提升有积极的作用。
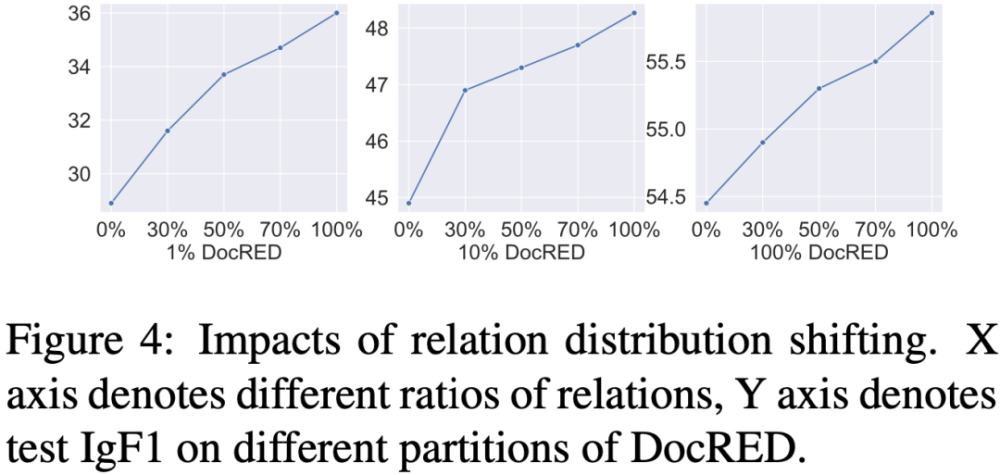

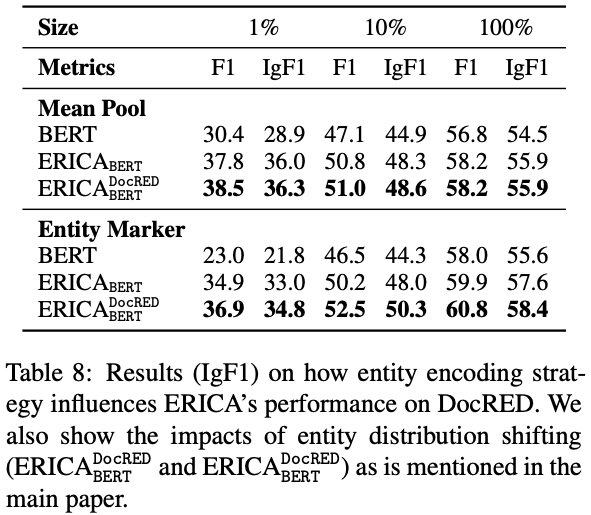
d) 除了使用均匀池化的方式来获得实体/关系表示,作者也尝试使用entity marker的表示方法来测试模型的性能。实验结果证明,ERICA对各种实体/关系表示方法均适用,进一步验证了该架构的通用性。
总结
在本文中,作者提出了ERICA框架,通过对比学习帮助PLM提高实体和实体间关系的理解。作者在多个自然语言理解任务上验证了该框架的有效性,包括关系提取、实体类别区分和问题问答。实验结果表明ERICA显著优于所有基线模型,尤其是在低资源的设定下,这意味着 ERICA 可以更好地帮助 PLM捕获文本中的相关事实并综合有关实体及其关系的信息。
迁移学习发展现状及案例探究
6月15日,机器之心最新一期线上分享邀请到本书作者、微软亚洲研究院研究员王晋东带来分享,介绍迁移学习的最新研究现状,带领大家从琳琅满目的研究工作中,找寻最本质的方法。













