

正文字数:9404 阅读时长:15分钟
本文整理自腾讯高级技术专家鲍金龙在LiveVideoStack线上分享上的演讲。他通过自身的实践经验,详细讲解了高性能视频推理引擎优化技术。
文 / 鲍金龙
整理 / LiveVideoStack
大家晚上好,非常荣幸又有这个机会来LVS,与大家一起探讨一些问题。我第一次参加LVS应该是2017年,现在已经接近4年的时间了。

今天的内容是推理引擎优化技术,当然有一个前提,主要是在端上。冯诺依曼体系的存储矛盾,几十年以来一直都是存在的主要矛盾。对于这个问题,如果是在NVIDIA显卡上,或者是国内的燧原NPU上,他们的解决方案是用最快的HBM内存、HBM2.5 3D堆叠的内存来增加总线的带宽,中间加上3~6层的Cache。但是在端上这么做其实是有问题的,比如端上的芯片的功耗,以及面积来出发的话,无论是GPU,还是DSP,L2的Cache基本是1 M左右,同时内存是所有的芯片共享的,还有LPDDR3、LPDDR4,功耗非常低,但是性能跟台式机DDR和HBM内存差10~20倍。所以,在端上的优化,还是需要从推理引擎的总体设计、算子本身的执行速度上,还有算子本身的可替换性上来入手,即从软件开发上来进行优化,因为硬件短时间内想提高10倍、20倍,实际上是非常困难的。
01
—
优化思路
目前的优化思路,虽然有五项,实际上可以分为三类。

第一类是从Framework角度来说,比如第一、二项,思路是改变一下数据排列,使计算流水线执行得更加有效。这是从Cache的利用率角度来做优化,可以降低总线访问,同时也能降低功耗。第三项就是算子本身做些优化,在不改变算子算法原理的情况下,看能不能执行得更快。第四项是旁路优化,就是通过等效替换的原理来进行。这里只列了两点,更复杂的优化还有,但目前时间有限,我们探讨不了太复杂的内容。第五项是,如果想使用运动补偿,那么就有运动向量从哪里来的问题,后面附加有一个运动向量的估计。
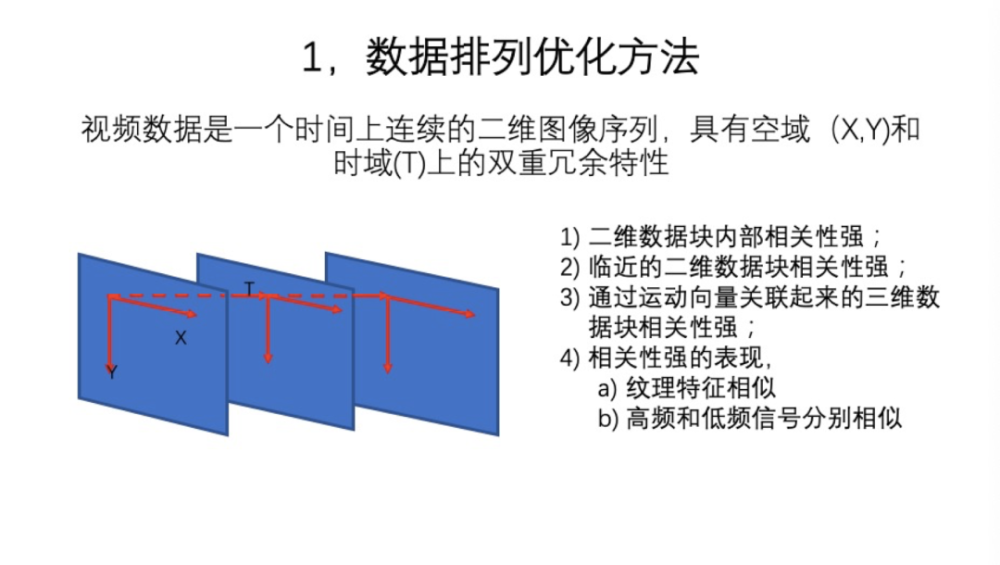
第一部分就是数据排列。这是一个非常基本的问题,视频数据是一个在时间上连续的二维图像序列,在空域上即单帧图像上,有水平和垂直两个方向的维度,在时间上和内容上有大量的冗余。视频数据有一个很强烈的特点就是,在帧内,比如分块的二维数据块内相关性比较强,比如平坦块都是平坦块,如果有纹理的话纹理都是连续的。第二个特点就是,临近的二维数据块相关性也比较强。第三个特点是,帧和帧之间,通过运动向量关联起来,它实际上就是一个Patch,三维数组相关性比较强。那么相关性强的表现是,不只纹理特征相似,还有高频和低频信号也分别相似(就是频谱特征相似)。这里是从时域和空域两个角度来看的。相关性就造成了可以让算法加速的很多机会,后面将逐渐展开讲解这些内容。

目前见到的常规推理引擎数据处理方式实际是Planar结构,它可能是多通道的,比如RGB,也可能是三个Channel,比如YUV、420格式、444格式。执行方式是行扫描,一行从左执行到右,然后第二行从左到右,跟早年电视机的扫描方式是一样的,扫描到一帧图处理完。这个方式是通用的,不管是什么类型的数据都可以执行完。但它也有一些问题。第一,这是按行执行的,那么数据局部的相关性没法从这种处理方式得到照顾。第二,这是整张图扫完,那么数据的吞吐量非常大。整张图扫描的方式可以理解为整张图是一个块,这个块就是最大块。一般来说,如果图比较大,比如Y通道数据有1~2 M大小,L2 Cache基本上就1 M,这就是一个很典型的Cache颠簸现象,就是说,处理完一个Filter的时候,接着处理下一个Filter的时候,你上次读的数据已经完全刷出去了,你需要重新再load进来。那么,问题相对来说比较严重了,无论是速度还是功耗,表现都非常差。

那么我们要解决这个问题,可以按照视频的编解码一样将数据分块,常规的分块就是8*8。一般来说,8*8的块能够充分照顾到纹理,有局部性,同时它内部也包含足够多的特征。块过大或者过小都各有利弊。那么,一般的分块存放是有跨度的。如果是8*8的块,第一个8个像素是在第一行,依次有一个很大的跨度,如果用现在的适合人工智能、大并发的指令来处理,比如AVX512,一次能做64个int 8的乘法,DSP就更大了,一般有128~768个像素,768的数据组织是RGB 16*16的分块,有三个通道,一次就能处理完。还有更多的,比如32*32。我们常常在网上看到一些NPU的设计,如马斯克的汽车导航用的NPU,或者是谷歌的TPU-1、2、3代,并发程度都一直在改进,但基本上都停留在这个水平上,不会太大,也不会太小。如果你是用420格式下有跨度地来读取,会发现这个效率是非常低的。比如一个8*8的块,需要8次寻址,8次读入,每次读入8个字节,只执行了一次计算指令,有8次写出。这样的效率其实非常非常低。那如何改进呢?
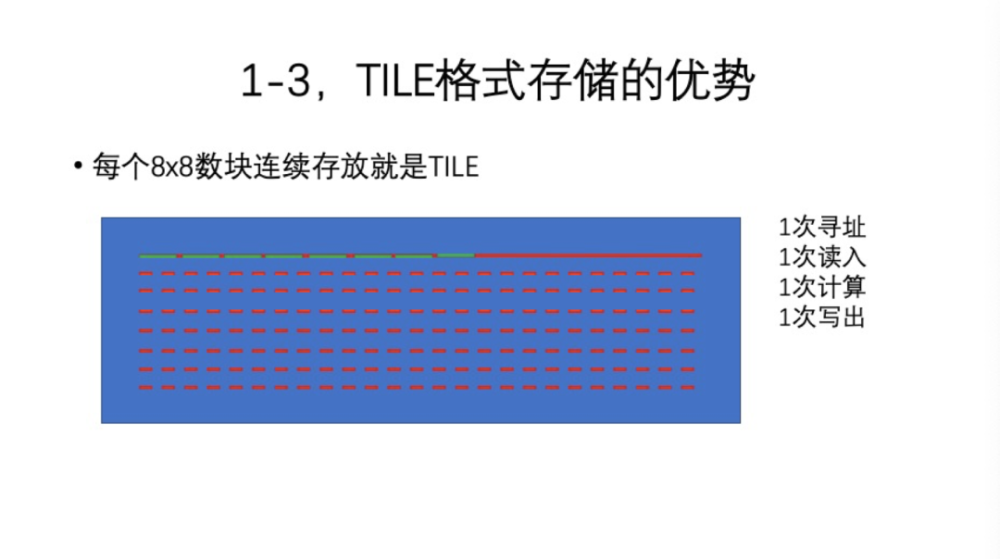
其实这很简单。改进方式就是,将8*8的块取消跨度,连续存放。比如将8个行连续放到64个字节里,后面的7个行都取消了,即这一行放了8行的数据。这样处理的优势是,比如处理8*8的块,只需要1次寻址,而且寻址是非常整齐的对齐地址,然后需要1次读入,1次计算,1次写出,这个速度就会快了7、8倍。但是,一般来说,我们达不到7、8倍的速度。原因就是,TILE格式数据想达到高效的处理,还要有数据转换、堆叠过程,运算过程中还有数据重排(后面依次会讲到)。

TILE格式是需要数据重排的。首先,输入的数据都是常规Planar格式的、RGB或YUV 420格式的,要转换就是取消跨度。但是一般的推理引擎都是需要复制一次,它不会在原始数据上直接处理,需要Pad-边界填充,同时可能也存在格式转换,重排可以和这个融合起来。转换函数permutation是一个执行非常快的指令,整个过程跟memcpy一样快,就是说,融合起来的代价就可以忽略了。其次,运算时候的数据并不是永远地址对齐的,有可能需要对运动向量地址不对齐的情况去做重排。上面这个图指示的就是如何在输入格式转换的时候重排得更高效。重排的时候,并不是一次读8个字节,或者一次读8行,而是一次读64字节*8行,经过重排以后,形成为8个8*8的数组。那么这个效率就是最高的,指令并行度都是饱和的、最大的。
接下来看一个地址重排的例子,这是最简单的例子。更多例子的大家有机会去试试。

当前假设A块地址是(0,0),相邻的是B、C、D,它们的间隔都是8,地址是对齐的。需要访问G块,地址是(6,5),所以,有一个运算向量。如果是420格式下,做一个不对齐的访问就可以了,或者做一个对齐的简单拼接。但是在TILE格式下,要多做一些工作。首先需要拼接到E,就是在A、C两块之间拼接E块,B、D两个块之间拼接出F块。但是这两个块跟G块还是有区别,它们位于一个水平线上的区域内,还要进行X坐标的重排。目前,AVX512的指令是这样的,移动64位,用三条指令来完成。如果以后有更先进的指令一次完成,那就更好。但很明显,设计AVX512的时候,没考虑到TILE格式。同时,注意,指令的后缀加了x,意思就是有个扩展。基本的Intel指令,比如c= 5,就是常量,但常量的效率太低了,一般用的是变量。下面有一个等价的实现,是通过另外一个permute、a,b两个向量重排之后,形成一个等价的变量align过程。

如果在高通的HVX上,就容易得多。高通的执行同样也是5行指令,但是前4个都是一类指令valign,它既支持常量,也支持变量,执行动作完全是一样的。最后,是类似AVX512 Blend的一个vswap操作,融合生成一个块。这些指令都是低延时指令,访存要快得多,所以代价基本上非常小。如果后续执行有进一步优化,可以把代价分散一下,那效果就会更好。
02
—
计算流水线
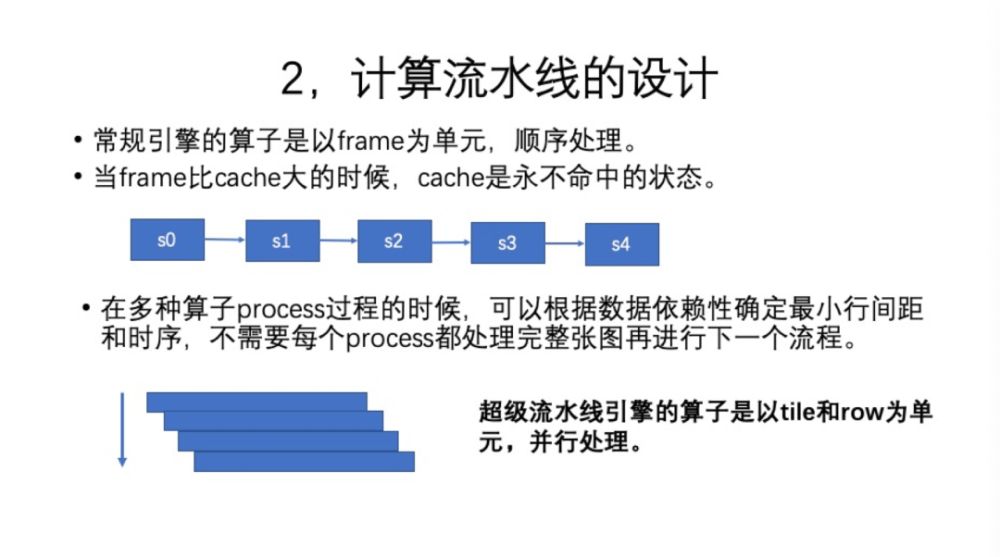
接下来,我们看第二部分。想要计算的时候需要一个新的方式Framework,原来是一帧、一个Filter在整帧上以raster scan的方式执行完,比如s0、s1、s2、s3、s4执行完,实际上Cache是永不命中的状态,Cache在移动端的速度非常慢。一般来说,根据我们实验数据,DDR内存访存的功耗,比芯片计算指令功耗的数据更大。要解决这个问题,我们想把所有这些过程的中间数据压缩到最小,比如Cache利用率,能提高一些。那怎么做呢?要设计一个超级流水线。就是说,在从s0到s4的多个步骤,这些Filter可以在Pipeline上并行执行。并行指的是数据的处理顺序从原来的每帧顺序依赖,转换为每行顺序依赖,这样从帧的角度来看,数据处理就是并行的。这样,数据基本都在Cache中,读取的时候并不进行过多的总线访问,功耗也非常小。
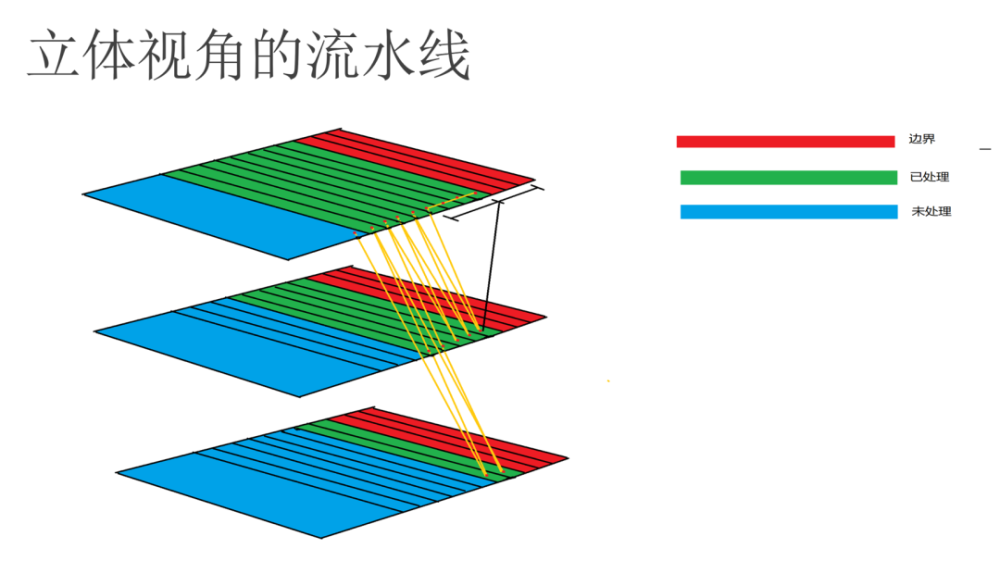
我们现在是以TILE或ROW,如果是420格式的也可以采用超级流水线,那么就是一行为一ROW。如果是TILE格式,那么除了行ROW,还需要一个二级结构TILE。
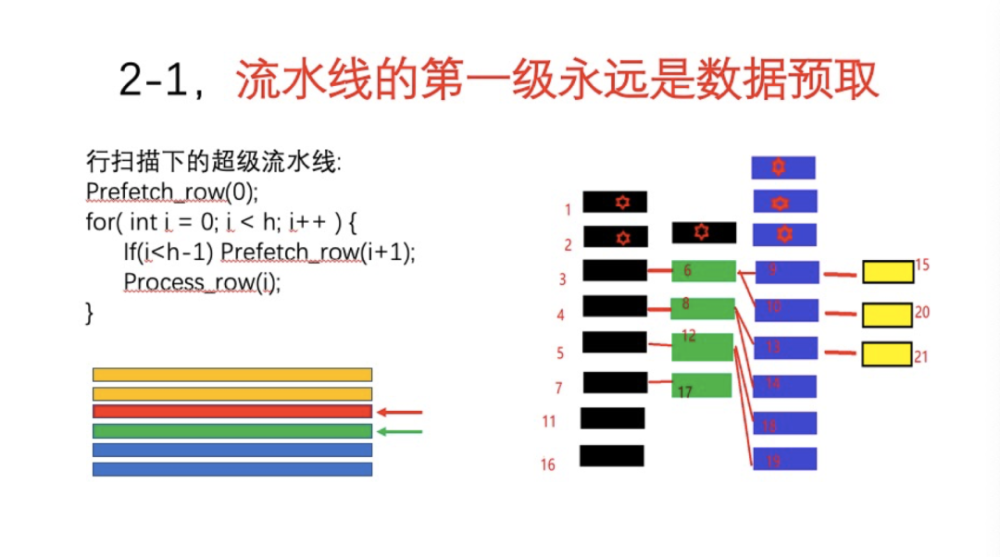
我们首先讲的是引擎的优化,但是,无论是普通引擎,还是优化的、特殊的、紧密堆积的引擎,数据预取是非常重要的。因为移动芯片上数据Cache非常小,如果数据不预取,基本都是不命中的状态。常规下,我们看到行扫描下的也是一种流水线结构。首先在循环开始之前,需要预取一行的数据,然后循环中首先要预取下一行的数据,然后处理当前行的数据。process_row函数处理时间比较长,一般都会有1000个Clock以上。那么一个数据从总线开始加载到Cache中去,时间一般粗略认为是100个Clock,有可能更慢,好一点机器可能是80个Clock,差一点机器是150个Clock。所以如果process_row执行过快,那么预取的效率就不够。比如处理的时候,prefecth_row并没有预取到,那么预取就失败了。但是如果处理一行,时间完全是够的。如果有很多很多种Filter同时进行,流水线有多级,数据预取跟raster scan相比效率就好多了。如图中所示,这个预取是依次执行的,比如黑色的一行,把预取和数据load放在一块,那么预取就做一次,后面都不需要做预取了,因为中间数据很小。原来你做了n次预取,现在实际上只做了第一次预取。如图所示,预取指针指向了绿色行,后面红色处理的要比它Delay 1行,后面黄色的就是处理过的。所以预取非常重要,如果没有预取,那么引擎就不可能达到很高的性能。
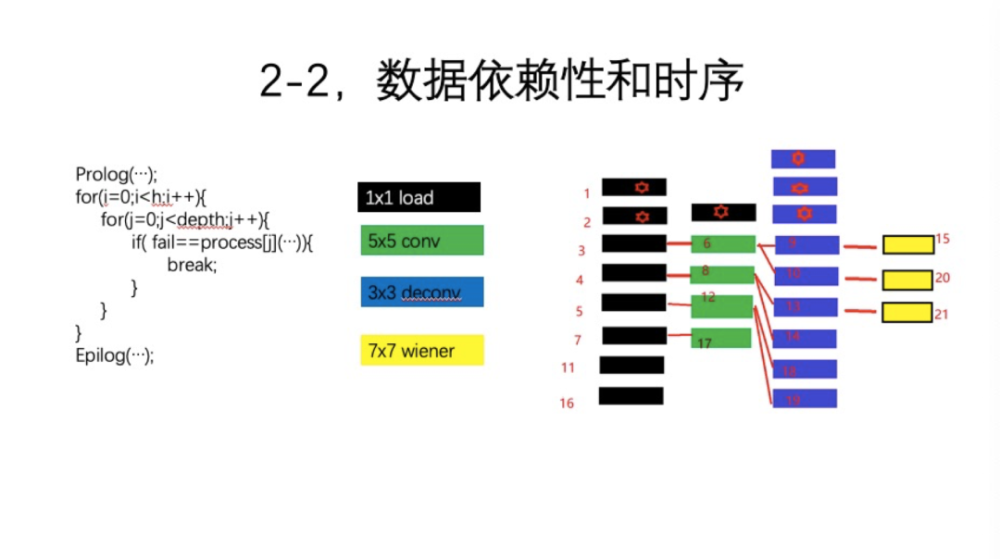
接下来是超级流水线的设计。如图所示,看看我们现在这个比较简单的例子,有四级。第一级是预取一个1*1的load,绿色是5*5的卷积,蓝色是3*3的反卷积(你就认为有就可以了),然后黄色是7*7的后处理。这显然对前方有一个数据依赖,如果其Tap条件不满足,后续的操作基本上不能继续。这里需要一个处理逻辑。看看上图中的代码,一次处理一个行,实际上就是使用4个process函数的指针,每次依次从上往下执行,比如执行load一行之后马上执行第二个。那么数据完整性显然不能满足。因为第二级Filter是5*5的,需要第5步处理完之后,第6步才能执行,所以它就Fail了 。那么一直走到5之后再去6执行,就发现数据完备了,那就6执行了。6执行后,下一级再处理了,尝试到9,那9显然不行。那么就从6直接break,返回到执行7,处理完之后,8就完备了。那再继续尝试的时候,发现9完备。之后就是下一级到15,15并不完备,然后又返回到11。11之后是12,12完了之后发现13和14都产生了。因为这是一个上采样操作,所以处理两行,这时候15就可以执行了。执行之后,20还没满足,返回到16。这个逻辑就是依次循环下去。实际上,这里执行效率比原来的、整张处理的效率要高得多,同时代码也非常简单。大家可以看一下,代码其实是很优美的,越优美的代码效率越高。
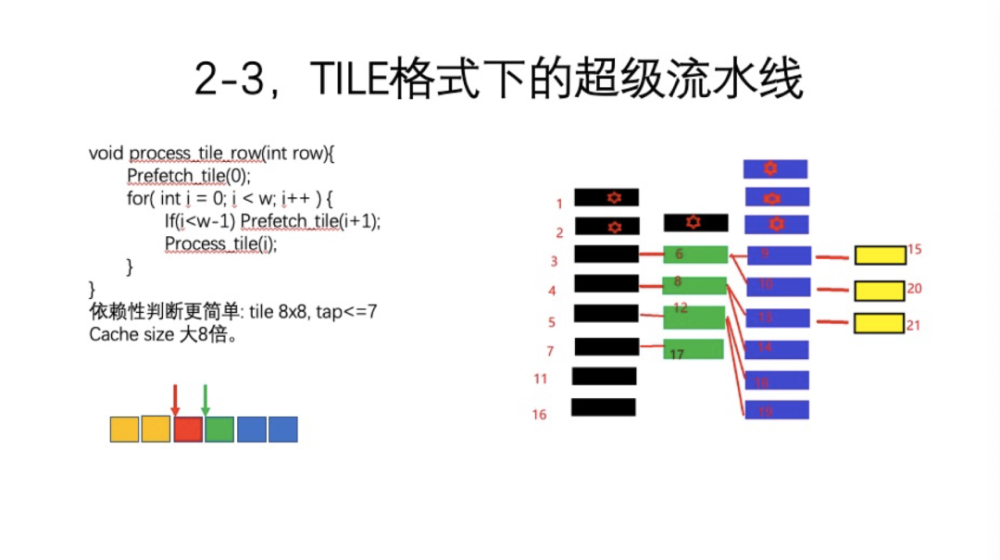
前面并没有明确讲是420格式还是TILE格式,无论哪种格式,数据依赖关系是一样的。TILE是一种特殊的格式,有一些特殊性。首先,预取就不应以行来执行,而是按照TILE块来执行。如图所示,绿色的是预取指针,红色的是处理指针指的是后面一块,黄色的块是已经处理过的。所以这里一个函数process_tile_row处理一行的时候,实际上是在循环外,预取第一个TILE,然后取下一个TILE,处理当前TILE,循环就执行完了。依赖性判断是,因为一个TILE是8*8,最大支持一个Filter的Tap是17,这很容易算出来,中心点加上两翼8+8。无论是卷积核还是滤波器都没有这么大,7*7、9*9就是极限了,一般是3*3、5*5就足够了。所以,这个判断比较简单,只需要看前面Filter的下一个TILE处理没有,没有处理就返回Fail,处理了就继续执行下去。
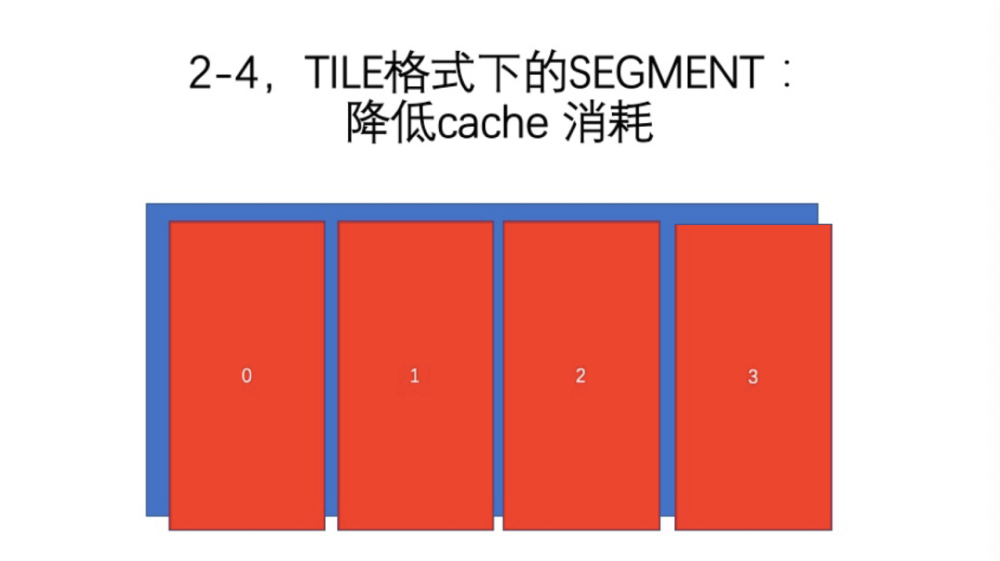
TILE格式下,一个TILE相当于原来的ROW的8行,Cache的消耗更大。一般来说,一个1080P单通道,在前面的流水线下,消耗是50 k。这个例子里只消耗50 k,这个应该远远超过大家的想象。我知道很多引擎在处理数据的时候,动辄消耗2、300 M的数据缓冲。如果设计这么一个引擎,只消耗了50 k的数据,那就是很惊人了。但实际上,这里有一个格式转换、输入输出转换,还最少需要2帧的缓冲。前面说过,(int数据类型的话)Cache算是50 k,但是数据类型有可能是浮点的、或者是int 32的,50*4 = 200 k就相对来说大一些,如果再乘8,就超过了L2的容量。那这个情况的处理很简单,在执行的时候,把数据分为多个TILE,现在把它叫作Segment。现在这一个Segment就是原来的四分之一,那么流水线的消耗自然也是四分之一,即压到了L2 Cache消耗范围内。这是一个很简单的变换操作。
03
—
算子

我们很快将TILE格式和流水线讲完了,下面进入第三部分。首先是算子合并。计算量非常小的算子的读取和写出的代价相对于计算来说是太大了。这里要做一个格式转换,比如int 8变成了int 32,float变成了int。比如简单的加减,甚至开方,有的软件模拟性的开方指令的计算量是比较大的,但是一般是硬件指令,这个Delay就很小。这种情况下,我们思路是,这个函数是一个加,执行就是一个循环,原来的算法是按行执行,这一行作为加写出。指令load a需要5个周期,load b需要5个周期,add只需要1个周期,写出store需要5个周期。效率确实很慢。实际上,如果load的时候,没有预取,那么周期可能就是50个或100个,这就是非常恶劣的情况,我们在很多工程代码里都看到。如果预取了,那么就是5个周期的损失。
图的右边是一个开方函数,也进行了类似的操作,读取、计算,然后写出。那么,我们认为开方需要消耗6个周期。这里,我们进行三个计算,对a和b分别进行开方计算,再将a和b开方的结果加起来,那么指令的代价加起来是48。

那么我们重新选一个函数,把这些操作都合并了,简简单单写成一行代码。这种情况下,我们再看一下代价,load a和load b都是5,一共是27,这样快了一倍。这是很简单的思路。
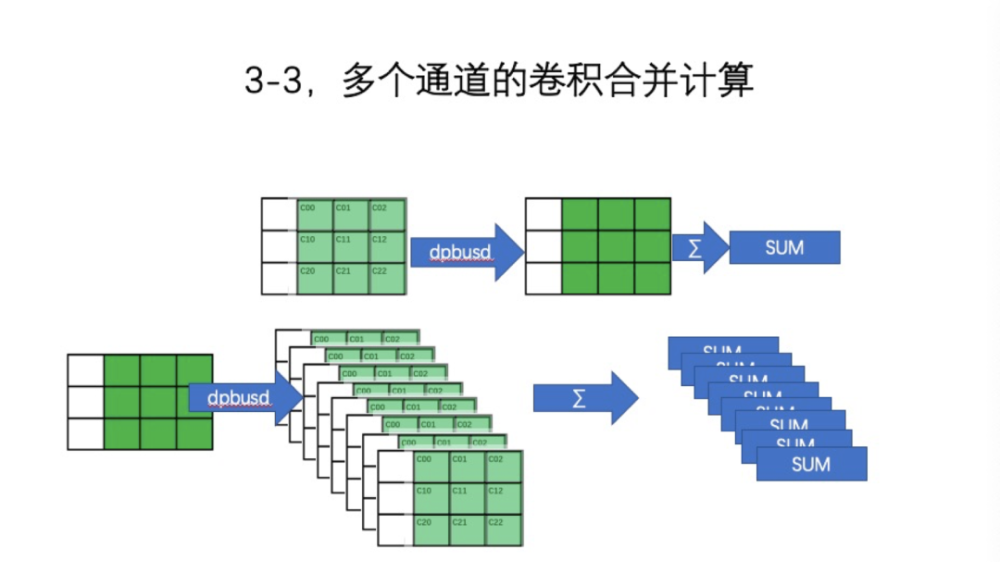
类似的还有一个多通道。通常,卷积是8组、16组、32组。如果我们做一个卷积,比如用AVX512、DPBUSD,在3*3的情况下,是不对称的,所以均匀分布到3个向量里,占用每个向量的Slot里面的低3位。数据也是要同样进行组织,每个向量经过DPBUSD计算,执行三次得出SUM。同时还有其他的代价,如读入。所以要尽可能一次将所有卷积和全做完,因为排阵方式是有代价的。需要Swap重排,重排了之后最好把它放在寄存器中,一次用完。这里的例子是8个,卷积核可以认为是const数组,一次一个循环就全做完了。完成之后直接输出。

前面说的算子融合,我们可能会有一个问题。我们在做模型的时候,一个Element、一个运算,单独是一个函数,是一个静态的依次执行。如果合并的话,那么排列组合非常非常多。假设我们现在支持180种运算,里面至少有90种是合并的,这个排列组合就是天文数字了,静态引擎是不可能的。在读入模型的时候,为每个模型单独构建一个执行代码。从时机来说,构建分三种。第一,在开发端上,比如用Mac笔记本,或者用服务器来编译的时候,直接生成一个SO,发行的时候把SO导到APK里面去。第二种,我们把模型放在端上,譬如手机端用ARM CPU来执行编译过程,将源代码算子合并,最后调用LLVM编译器,生成优化代码,让ARM CPU来完成。第三种,是在Device上完成,OpenCL就是在GPU上编译的,在DSP上也是可以的,实际上,这完全看你自己的选择。从安全性角度来说,我们才需要区分Host和Device,否则Host就可以了。但是,这里有一个问题,因为大家都用过OpenCL,在端上需要编译代码,编译代码的时间实际上比较长,一般是几百毫秒。一般我们在做A/B实验的时候,APP启动多出来几百毫秒,这是比较致命的。
如果你觉得这个比较费劲,那么还有另一种办法。第二条我建议的是,优化好的二进制不需要用编译器来编译了,直接把每个算子变成二进制unsigned char数据,然后在运行前根据模型把这些算子unsigned char数据直接拼起来,这时候就不需要优化过程。假设拼接代码优化水平很高的话,拼接代价是可以忽略的,一般拼接速度快到千分之一秒。
04
—
算子旁路优化

接下来是算子旁路优化。前面首先讲的是如何让Cache利用率更高,功耗更低,然后是让算子执行效率更高,但是算子本身并没有进行算法优化。旁路优化有一个基本原则。一方面是处理的简单特征,梯度方向,当前8*8的块分为两部分区域,梯形的一个Edge,这些特征可以通过简单快速算法获取,不需要比较复杂的模型,性价比比较高。另一方面,复杂特征想要进行计算,只有用深度方法。这两方面是相辅相成的,在一定条件下,它们可以互换,快速算法可以替换深度算法。也就是说,某些数据块用简单算法的输出,误差可以接受,或者是零误差,那么局部替换就是可行的,即一块变化了,整个网络输出不会受影响。一般来说,判断替换需要一个算法。比如运动向量,残差是否是0,预判算法都是有代价的,代价比收益要低很多才行。如果替换了之后,速度提升了3倍,同时有百分之十的代价,那么这两部分比较,收益还是比较大的。否则,这件事就不用做了。我有一个亲身经历,对一个算法做了纹理复杂性的预判,用TV(Totally Variance)方法,但实现有问题。比如一个720的图需要判断其代价是3~6ms,如果算法不进行任何旁路全走一遍,在3~6 ms内也走完了,而经过预判后,速度反而更慢了。

接下来我们看看纹理复杂度分析。常规复杂度实际上也是一个TV算法,但是它的实现方式可以非常快,代价没有多大。比如一个8*8的块,首先要判断它是平坦的,算一个平均值avg。如果它是一个平坦块,每个点跟平均值的方差,或者等价的abs,代价小于一个值或者就是0,那么纹理就是平坦的。这样做的好处是,比如一个卷积运算,每个点需要做一个乘法,但在平坦情况下,它会退化,avg值都是一样的,所以提出来之后,等号右边的参数和就变成一个常量,o(n**2)或者o(n**3)的运算退化为o(1)了。当然还有其他更复杂的情况,思路是类似的,先要判断,在旁路成立的情况下进行等价替换。我们看看下面的例子:梯度方向的判断,就是在一个方向上进行TV运算。比如在45度的方向取了8个点,8个点跟平均值的方差非常小,或者是0,这个方向显然是一个边界。也可以计算多个方向的梯度,用Sobel算子、拉普拉斯算子,但是从可靠性角度来说,还是推荐用TV的方法。

平坦性纹理可以有一个很明显的退化。跟它类似的还有一个明显的o(1)的退化,即运动补偿。编解码只有一个像素补偿,但是深度推理引擎必须各个环节都做,不能因为像素复制了,周围的网络中间数据就不计算了,网络输出就不等价了。所以在各个层次上都需要做足运动补偿。第一个是像素补偿。两个数据块残差为0,我们对这两个块分别做滤波器处理,可以认为这两个块的结果也是残差为0。做完F(b0)后,F(b1)就不用做了,直接复制过来就可以了。这实际上也是o(1)的操作。第二个是卷积补偿。卷积有中间输出结果,如果只是做了运动补偿,中间数据空了,那么卷积像素是有依赖的,网络的输出结果就不正常了,所以,卷积的中间结果也就是等价滤波器的中间结果,也需要进行运动补偿。同时输出的重要中间数据,比如featuremap,也需要补偿。这些补偿都是有代价的,要估算一下复制的代价,或者直接硬算的代价。一般来说,在PC上,或者没有功耗压力、带宽比较高的情况下,运动补偿的收益是非常大的。在移动平台上,如果是内存总线非常慢的情况下,要衡量一下替换多复杂的滤波器。一般有一个平衡点,过了平衡点就是有收益的,如果不到的话,那么运动补偿就是失败的。
05
—
快速运动估计
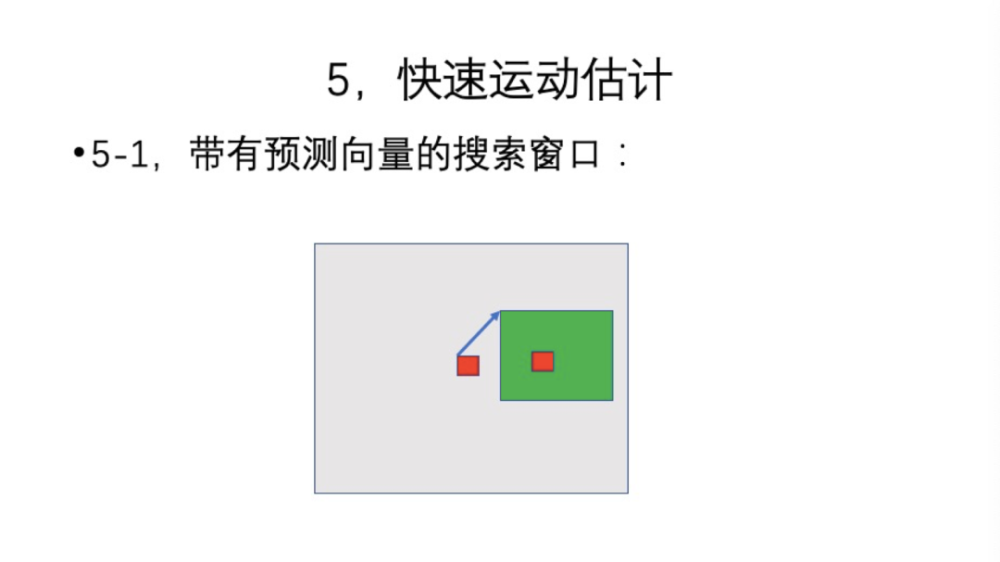
下面进入到最后一部分,我们介绍快速运动估计。运动补偿都需要一个Block Match的过程,或者是光流,每一个像素都需要一个运动向量,一般我们就使用8*8块的运动向量。通常,我们的算法跟解码器相结合,可以获得一个运动向量,但是编解码的时候都是有残差的,这可能对你的算法的干扰非常大,导致大多数情况的运动向量并不能使用。这种情况下,你需要自己获取这个运动向量。如果是常见的编码器上的运动估计,代价是特别庞大的,会比你本身的深度算法还要慢,所以没有必要用这种方法来获取。但是,近年来涌现了一些快速算法,就是快速运动估计,这个算法有几个特征。第一,跟原来算法都使用一个大的搜索窗口相比,快速算法窗口上有初始化的预测运动向量,因为这个预测运动向量的存在,窗口可以变得很小。我们假设匹配的目标如上图所示,原来没有优化过的搜索算法要使用一个很大的搜索窗口,而快速算法有了预测向量后,窗口可以做得很小,即搜索次数很小,就可以收敛了。因为预测向量是通过不同渠道获取的,它不一定符合,它有各种变化,跟像素的复制不一样,向量不能直接用,你要重新执行搜索过程,但是这个搜索比没有预测的窗口要快得多。
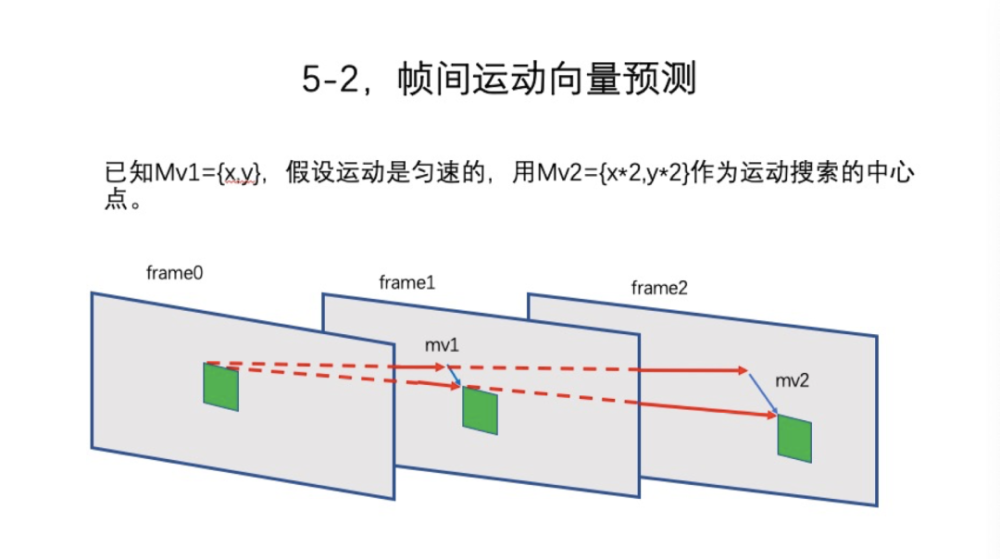
那么,预测向量如何获取呢?我们假设有一个序列,从frame0到frame1,mv1已经通过了搜索的方式获取了。我们可以预测,比如从frame0到frame2做一次搜索,那么就可以认为当前这个块是匀速运动的,那就把这个运动向量引申到frame2上,mv2就是很简单,mv1乘以2就可以了,在此基础上确定这个窗口,再重新进行搜索。但是,还有其他的方法,比如反向搜索,从frame1到frame0。这个点所在的Block就可以用这个运动向量,运动向量反向指向frame0的搜索,同时frame2也是可以用的,也可以反向进行。可能性很多,在新版本VVC里应该有类似的算法,这并不复杂。
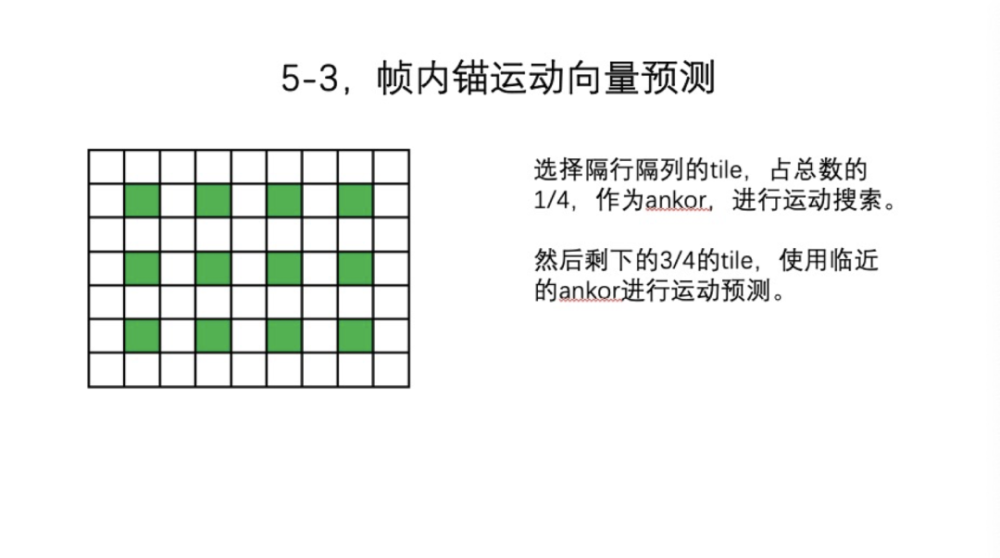
接下来是第二种获取方法,即Ankor(锚)。什么是Ankor?如图中所示,数据分了很多TILE,但不是所有的TILE都进行搜索,我们只搜索隔行隔列,是总数的四分之一,再将这四分之一的TILE作为Ankor,进行运动搜索。剩下的四分之三,就使用临近的Ankor获得的运动向量作为预测向量。不同的体系结构,Ankor的选取和执行顺序有变化。比如是GPU,那么Ankor之间没有时间依赖,同时搜索就可以了。如果是DSP CPU,可以用raster scan,那么下一个Ankor可以用前一个Ankor,这样就更快些。如果是并行,也没有任何问题,四分之一数量Block搜索的代价比较小。
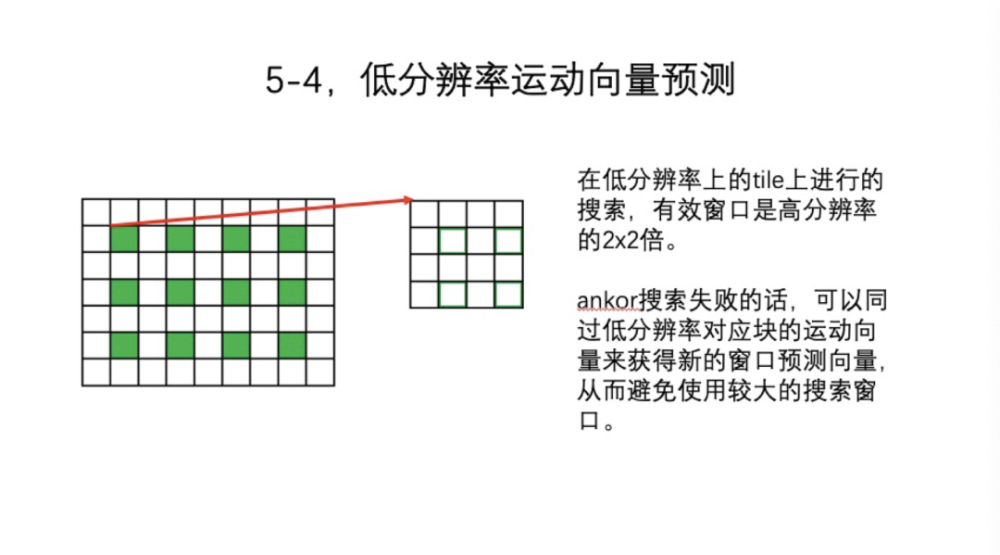
接下来还有一个问题,失败的可能性有两种。第一,预测的基本向量方向不对。第二,窗口不够大。这两种情况都可能造成Ankor搜索失败。一般,我们不会放大窗口,或者原地转圈换方向的操作,而是在低分辨率上进行完全一样的搜索,就是搜索算法不变。但是因为分辨率是四分之一,实际上等价窗口是2*2,在低分辨率的TILE进行搜索,把运动向量乘以2,就作为当前TILE的初始化。我们获得新的窗口,避免使用速度比较慢的较大的搜索窗口。实际上,可以将其看作是2级的金字塔,更复杂的会有3级。但因为我们有三种预测方法,那么3级的收益就不是很大了,用2级就可以了。
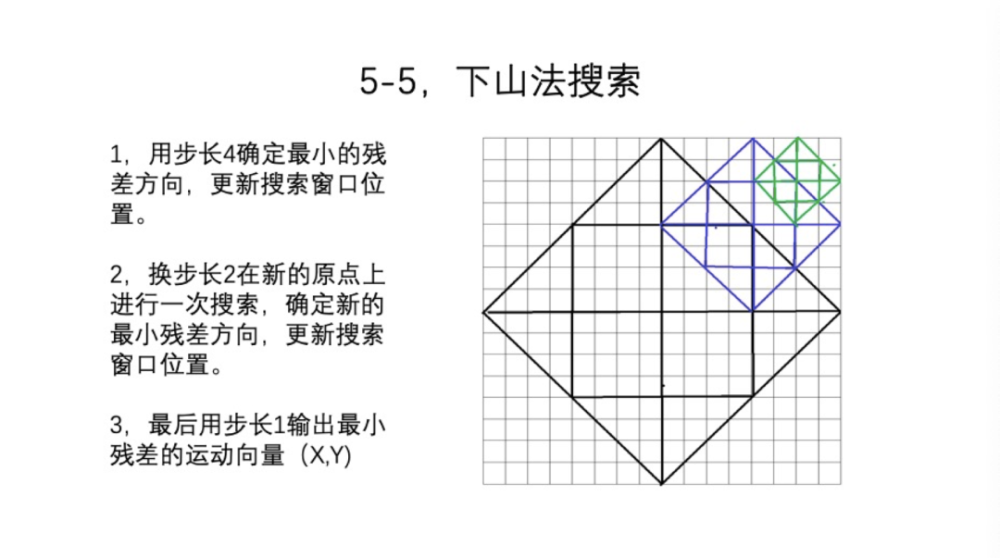
最后一点是搜索。我们现在有运动向量,有窗口了,那么搜索怎么进行呢?传统的raster scan就是一行一行地搜索,16*16的结构,要搜索256次,这显然是不可以接受的。我们引出了下山法搜索,用变步长。第一次步长是4。比如16*16的窗口下,搜索13个点的菱形,第一次搜索13个点,然后用残差最小的点作为新的方向。第二次换成步长2,就是蓝色的区域变成新的搜索窗口,如果得到一个非常荒唐的结果那就失败了。如果残差继续缩小,步长换为1,就是绿色的窗口,最后输出最小残差的运动向量。
06
—
优化收益数据
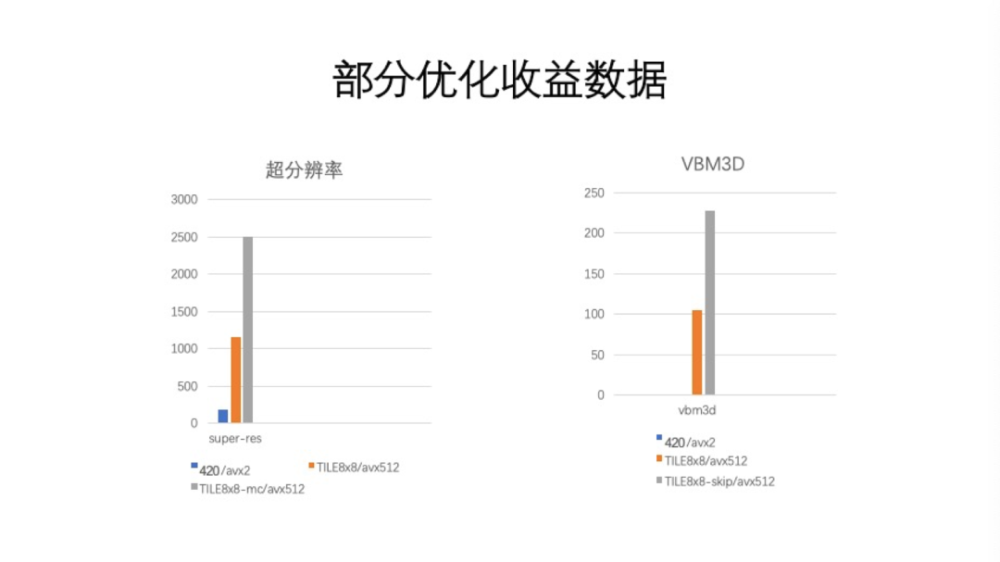
到此为止,快速的运动估计就介绍完了。前面讲了三种优化方法,更多方法这次没有讨论。一般这三种优化方法都做的话,会得到一个很明显的收益。比如,第一种方法有3倍收益,第二种方法也有3倍收益,第三种方法有4倍收益。如图所示,这里举了两个例子。第一个是超分辨率。如果是用传统的420格式,AVX2指令优化,那就不到200 fps。因为这个算法是面向移动端的。如果在PC上,数据是比较吓人的。但是优化之后,比如使用了TILE格式,没有使用纹理分析运动补偿的情况下,速度非常快,到1000 fps以上。那么,再进一步,把纹理分析、旁路分析都加入的时候,速度又拔升了百分之四十到百分之六十。第二个例子是传统算法VBM3D,它的收益也很夸张,因为我们用了快速运动估计算法。它的主要运算都是在Block Match上,我们把Block Match进行加速之后,收益非常明显。如果是420格式下,网上的开源实现,用5帧序列,AVX2优化,1080的数据的性能是1 fps,如果是8*8 AVX512,那么就是超过100 fps。如果是加上Early Skip 模式,跟运动补偿不一样,这个不是运动参考的方式。这个模式是指进行DCT三维变换的时候,某些情况下可以超前处理一部分数据。Early Skip也会产生1倍的收益,最终在1080p上达到220 fps。这基本上认为已经达到实时的程度。一个非常缓慢的1 fps的视频算法,提升到220 fps,就是从离线场景进入到实时场景这个过程。
今天的分享就是这些内容。谢谢大家。
讲师招募 LiveVideoStackCon 2021 北京站













