
机器之心专栏
作者:徐迅
为了促进视觉功能可供性在真实场景中的研究,在这篇CVPR 2021论文中,来自华南理工大学等机构的研究者提出了基于 3D 点云数据的功能可供性数据集 3D AffordanceNet。基于此数据集,研究者提供了三个基准任务,用于评估视觉功能可供性理解。
简介
功能可供性 (Affordance) 理解关心的是人类和环境之间的交互。例如,一个人可以坐在椅子上,抓取一个杯子或者提起一个背包。能够从视觉信息中理解物体的功能可供性对机器人在动态且复杂的环境中执行操作是至关重要的。物体功能可供性理解具有广泛的应用,例如行为预测和物体有效功能预测等。在计算机视觉领域,已有相关工作基于视觉信息进行物体功能可供性研究,即视觉功能可供性(Visual Affordance)理解。许多工作基于深度神经网络构建算法,因此需要大量的标注数据进行网络训练和性能测试。现有的物体功能可供性数据集大都从 2D (RGB) 或者 2.5D (RGB-D) 传感器中采集数据,其中 2D 数据缺乏几何信息,而 2.5D 数据常常因为采集的深度信息方差过小导致几何信息不够丰富。然而,物体功能可供性理解需要足够的几何信息,例如:关于抓取的功能可供性与物体上的垂直结构高度相关。现有数据关于几何信息的缺失和匮乏使得相关工作仍然无法对物体功能可供性进行充分并完善的研究。
当前三维点云研究集中在 ShapeNet、PartNet 等数据集,其中 PartNet 的提出也受到了功能可供性的启发。然而,PartNet 数据集以语义分割和实例分割作为支撑任务,其标注并未真正考虑人或机器人可以与物体开展的交互。并且分割任务在每个点云类别上独立展开,即在做分割任务时假设物体类别已知,这样的实验设置违背了与真实场景中各种物体同时存在或物体类别比较含糊的情况。为了促进视觉功能可供性在真实场景中的研究,来自华南理工大学等机构的研究者提出了基于 3D 点云数据的功能可供性数据集 3D AffordanceNet,该数据集基于现有的大型 3D 点云分割数据集 PartNet,通过一个 3D GUI 标注工具,引导标注者在预先定义好的功能类别上进行数据标注,并利用标签传播算法将标注者的标注扩散到整个物体点云上,以获得点云中的各个点关于具体功能的概率值得分。如图 1 所示,在数据标注的过程中,研究者发现人们所感知的物体功能可供性与 PartNet 数据集中提供的物体部件标签只有部分重叠,证明了在 PartNet 数据集基础上进行物体功能可供性标注的必要性。

图 1:3D AffordanceNet 数据集样例
研究者在所提出的 3D AffordanceNet 数据集基础上,提出了 3 个视觉功能可供性理解任务,并对利用半监督学习方法进行视觉功能可供性理解以利用未标注的数据样本的方式进行了探索,三个基线方法被用于在所有任务上进行评估,评估结果表明研究者提出的数据集和任务对视觉功能可供性理解在具有价值的同时,也具有挑战性。

论文链接:https://arxiv.org/abs/2103.16397
实验代码:https://github.com/Gorilla-Lab-SCUT/AffordanceNet
项目网页:https://andlollipopde.github.io/3D-AffordanceNet/#/
3D AffordanceNet 数据集
为了构建 3D AffordanceNet 数据集,研究者首先通过参考相关文献定义了功能类别,并从 PartNet 数据集中采集了用于标注的 3D 点云数据,覆盖了室内场景中的常用物体类别,同时开发了一个问答式的 3D GUI 标注工具进行数据采集,最后利用标签传播算法获得完整点云的功能可供性标注。
具体而言,研究者参考相关文献,选择了 18 个适合 PartNet 数据集中 3D 物体的功能类别:抓取 (Grasp)、提起 (Lift)、包含 (Contain)、开启 (Open)、躺 (Lay)、坐 (Sit)、支持 (Support)、抱 (Wrap-Grasp)、倾倒 (Pour)、显示 (Display)、推 (Push)、拉 (Pull)、听 (Listen)、穿 (Wear)、按 (Press)、切 (Cut)、戳 (Stab)、移动 (Move)。研究者根据 PartNet 数据集中物体的属性和与人或机器进行交互的功能,将筛选出的 18 个功能类别与各个物体类别进行关联,例如,一张椅子是可以 “坐” 的而不可以 “躺” 的。标注者可以在各个物体类别所支持的功能类别上进行标注,需要注意的是,标注者可以自由地决定物体在预定义的功能类别中所支持的类别,因此有些物体不会被标注到所有为此物体类别预定义的功能类别。
研究者开发了一个基于网页的问答式 3D GUI 标注工具。给定一个 3D 物体模型,标注者可以随意旋转,平移,缩放 3D 模型,以便从任意角度充分地观察物体。如图 2 所示,标注者将首先被问及物体所支持的功能有哪些 (What affordances does this shape support?),在选择了物体所支持的功能之后,标注者将根据问题的引导,在物体上标注支持某个功能的关键点。标注者还会决定所选择的功能是否会扩散到当前关键点所属部件的临近物体部件,若是,则标注者还将会选择被扩散到的临近物体部件,若否,则标注者继续在同一个部件上进行关键点标注。引导标注者标注关键点的问题在图 3 中给出。
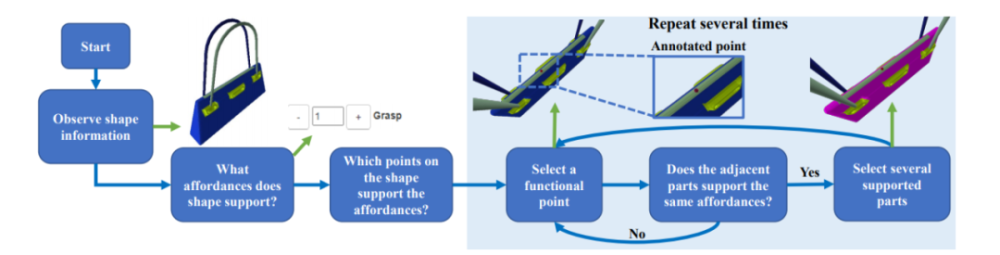
图 2:数据标注流程

图 3:问题示例
在获得了各个 3D 物体关于不同功能的关键点坐标后,研究者通过最远点采样算法在 3D 物体模型上密集采样 10000 个点,并利用标签传播算法将标签从关键点传播到 3D 物体上各个点上以获得带有完整标注的点云。具体而言,首先基于采样得到的 3D 点云构建一个 k 最近邻图,并计算得到邻接矩阵 A:
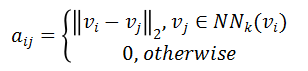
其中v是点的xyz坐标,NN_k是点的 k 最近邻点。接下来通过公式将邻接矩阵对称化,并利用公式获得标准化后的邻接矩阵,其中D是度数矩阵。最后所有点的得分S通过闭式解得到,其中是一个 one-hot 标签向量,1 代表被标注的标签。α是一个用于控制S的下降速度的超参数,在实际中被设置为 0.998。最后将S进行归一化使得其值域位于 0 到 1 之间以表征概率分数。部分标签传播过后的数据样例在图 4 中给出。

图 4:部分数据样例
数据集的统计特性
最终 3D AffordanceNet 数据集为涵盖了 23 个物体类别的 22949 个物体提供了定义良好的视觉功能可供性标注,每个物体类别最多被标注有 5 个功能类别。从功能可供性的角度来看,18 个功能类别总共有 56307 个物体功能可供性标注。值得一提的是,每个点可以同时被标注为支持多个功能类别。图 5 和图 6 展示了数据集的统计特性。
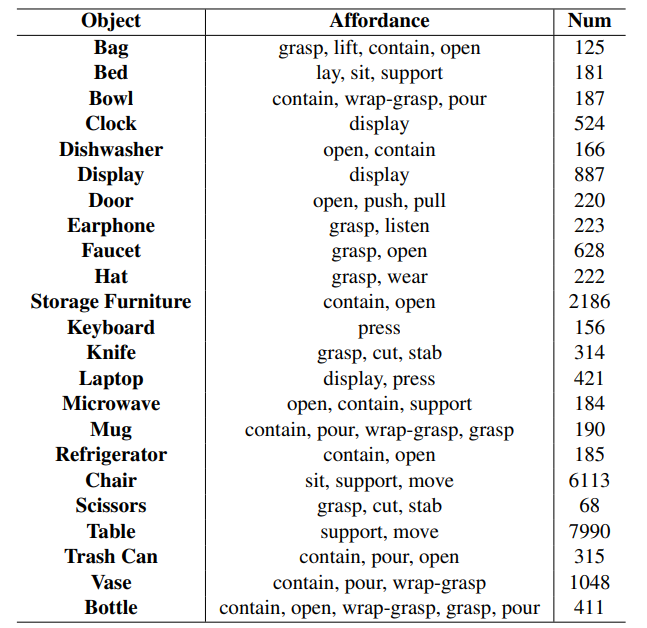
图 5:数据集统计特性,每个物体类别支持的功能类别及其数量

图 6:每个功能类别被标注的物体数量
实验与基准
研究者将数据集按照 70%、20%、10% 的比例依次划分成训练集、验证集和测试集,并基于所提出的数据集提出了三个视觉功能可供性理解任务:完整点云 (Full-Shape) 功能可供性估计、部分点云 (Partial) 功能可供性估计和旋转点云 (Rotate) 功能可供性估计,并进一步探索了使用半监督学习的方法利用未标注数据进行点云功能可供性估计的可能性。三个基线方法被用于评估所提出的任务:PointNet++、DGCNN 和 U-Net、PointNet++ 和 DGCNN 的实验都采用了它们论文中的默认参数,而对 U-Net 则采用 PointContrast 提供的预训练参数进行初始化。
完整点云功能可供性估计旨在估计完整的点云上各个点支持的功能类别及其对应的概率分数。所有网络的分类头部都被设置成各个功能类别单独的分类头部,而各个分类头部共享同一个骨干网络。骨干网络提取的各个点特征经过若干线性变换层,最后通过一个 sigmoid 函数得到点关于某个功能类别的概率得分。研究者使用交叉熵损失函数和考虑了正负样本的 DICE 损失函数训练三个基线网络:
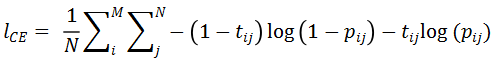
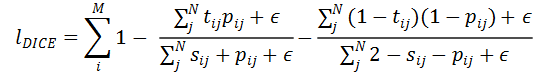
其中M是功能类别的数量,N是物体数量,是标注第j个点关于第i个功能类别的标注得分,是网络预测的得分。最终的损失函数为。网络性能的评估指标采用平均准确度 (mAP),均方误差 (MSE),ROC 曲线下面积 (AUC) 和平均交并比 (aIOU),所有性能指标都在各个功能类别上计算之后取所有类别的算术平均值作为最终指标。特别的,对 aIOU,研究者以 0.01 的间隔从 0 到 0.99 间取阈值将预测得分二值化,计算所有阈值下预测得分与标注得分的 IOU,最后 aIOU 即为所有阈值下的 IOU 算术平均值。除了 MSE 外,其余所有指标的计算都将标注得分进行二值化处理。
部分点云功能可供性估计在部分可见的点云上进行功能可供性估计。由于实际场景中传感器扫描得到的点云数据不一定是完整的,因此在部分点云上进行功能可供性估计也是研究者考虑的重点。具体而言,研究者通过在 (-1,-1,1),(1,1,1),(1,-1,-1),(-1,1,-1)四个位置设置相机获取固定视角下的部分点云数据,在三个基线网络上以与完整点云功能可供性估计相同的方式进行训练和测试。
旋转点云功能可供性估计在旋转后的点云上进行功能可供性估计。PartNet 中的 3D 点云均处于标准姿态下,研究者提出两种旋转实验设置:z/z 旋转和 SO(3)/SO(3)旋转,前者将点云沿着重力轴方向进行随机旋转,后者将点云沿着三个轴方向进行随即旋转。对各个旋转实验,在训练阶段,对每个点云进行随机旋转采样输入进网络,在测试阶段,将网络在预先随机采样好的 5 个旋转点云下进行测试。训练和测试方法与完整点云功能可供性估计相同。
如图 7 所示,三个基线网络在提出的三个任务上的性能随着任务的难度逐渐下降,其中 SO(3)旋转实验的性能下降最为明显,三个基线网络的 mAP 均下降了 5~10% 的百分点,而即使在完整点云上的评估性能也存在较大的提升空间,说明了 3D AffordanceNet 和提出的任务对现有的网络是具有挑战性的,适合于视觉功能可供性理解的网络结构和训练方法仍然有待研究。
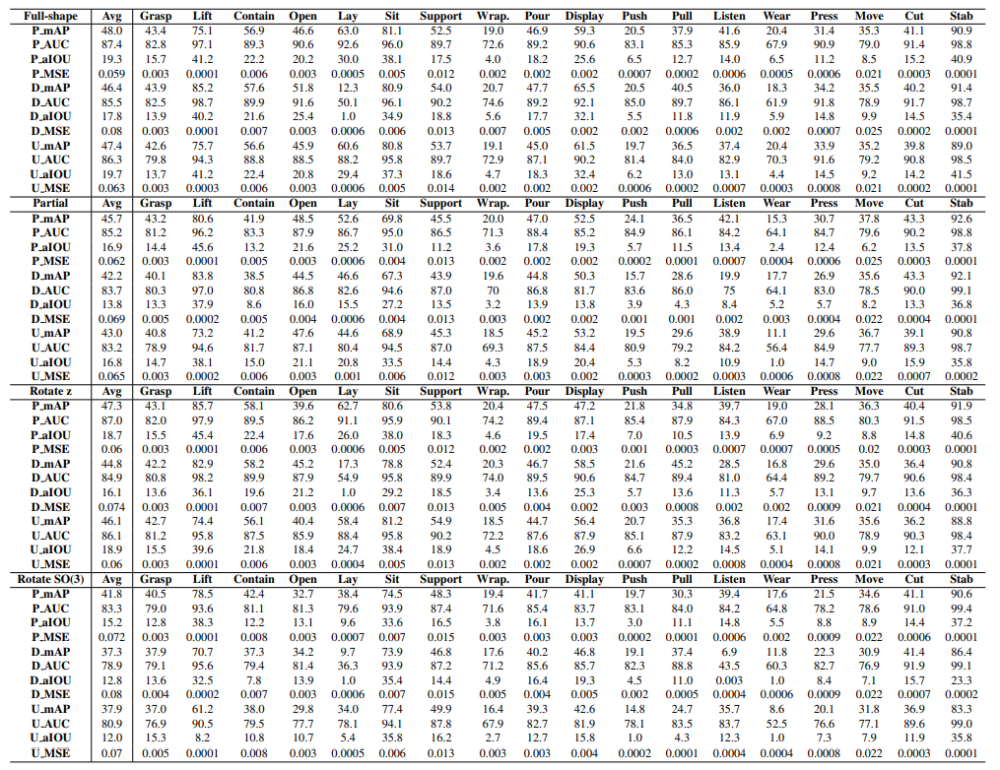
图 7:实验性能评估结果。P 代表 PointNet++,D 代表 DGCNN,U 代表 U-Net
图 8 展示了 PointNet++ 的部分实验结果可视化图像。从第二行可看出,PointNet++ 在完整点云上预测的结果是合理并符合预期的。第三行的部分点云预测结果则在一些功能类别上失败了,例如在包含 (Contain) 类别上网络忽略掉了一些部分观测到的平面。第三行和第四行的预测结果表明网络在旋转点云上性能较差,例如对打开 (Open) 类别完全预测错误,对包含 (Contain) 网络预测分数较低。
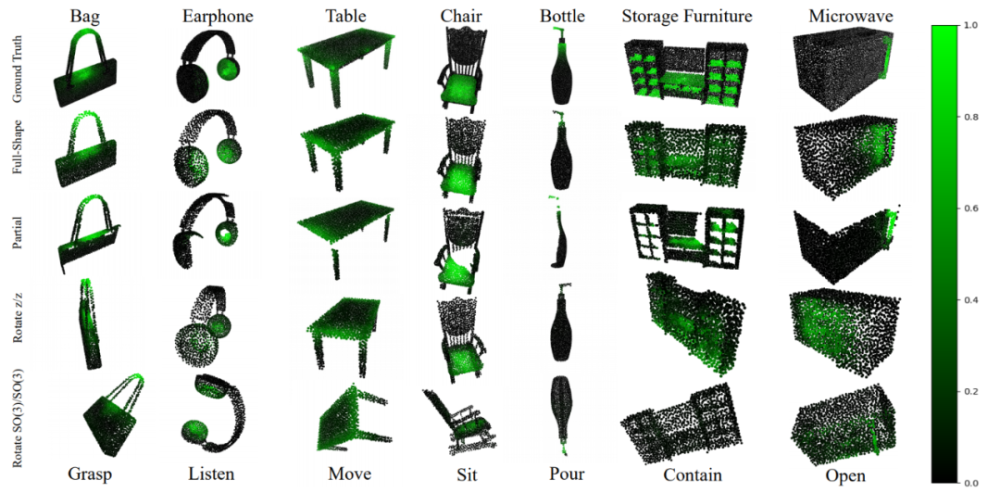
图 8:PointNet++ 的实验结果可视化
标注功能可供性是一个较为困难的标注任务,因此会带来较高的人力和时间成本。为了探索利用未标注数据进行视觉功能可供性理解任务的可能性,研究者进行了半监督学习的实验。研究者使用 DGCNN 作为骨干网络,在原有训练集的基础上采样了 1% 的数据作为带标注数据,其余的为未标注数据,并采用最新的半监督学习方法虚拟对抗训练 (VAT) 训练网络,VAT 降低未标注数据及其增广数据的预测结果之间的均方误差:
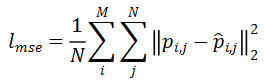
其中是增广数据的预测概率得分。为了增广数据,首先施加一次对抗攻击,对应的对抗扰动则与原始点云相加作为增广点云。最后用于半监督学习功能可供性估计的损失函数为:
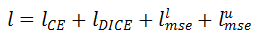
其中分别是标注数据和未标注数据的均方误差损失。研究者采用半监督学习在完整点云功能可供性估计任务上训练 DGCNN 网络,并与只使用 1% 数据全监督训练的 DGCNN 网络进行性能比较。如图 9 所示,通过利用大量未标注的数据,与半监督学习训练的网络性能相比,只使用少量标注数据全监督训练的网络的性能有 1~2% 的百分点的提升,说明未标注数据可以为功能可供性学习提供有用的信息,利用未标注数据提升网络的性能应获得更多人的关注。

图 9:半监督与全监督性能比较
CVPR 2021 线下论文分享会
6月12日,北京望京凯悦酒店。CVPR 2021 线下论文分享会将设置Keynote、论文分享和Poster环节。
4个Keynote、12篇论文分享日程已确认,欢迎大家报名学习。
作为一场开放的学术交流活动,我们也欢迎 CVPR 2021 的论文作者们作为嘉宾参与(现只剩Poster席位),请在报名页面提交演讲主题、论文介绍等信息,我们将与你联系沟通相关事宜。













